


Gemini 2.5 Pro 是 Google 最先进的 AI 模型,专为深度推理和高质量响应生成而设计。在关键基准测试中表现卓越,展现出卓越的逻辑能力和编程水平。该模型针对动态 Web 应用、自主代码系统和代码适配进行了优化,提供高性能体验。凭借内置的多模态能力和扩展的上下文窗口,它能够高效处理大型数据集,并整合多种信息来源,以解决复杂问题。
网站 AI模型网页 | |
提供商 提供该模型的实体机构 | |
聊天 输入消息开始聊天 | - |
发布日期 模型首次发布时间 | 1 年 ago 3月 25, 2025 |
模态 模型可处理的数据类型 | 文本 图像 语音 视频 |
API提供商 提供此模型的供应商(非完整列表) | Google AI Studio, Vertex AI, Gemini app |
知识截止日期 模型知识最后更新时间 | - |
开源 模型代码是否公开可用 | 否 |
输入定价 处理提示词中token的成本 | 不可用 |
输出定价 模型生成token的成本 | 不可用 |
MMLU 多任务语言理解测试 - 评估数学、历史、法律等57个学科的知识掌握 | 不可用 |
MMLU-Pro 增强版MMLU基准测试,包含更难的推理题、更多选项集并降低提示敏感性 | 不可用 |
MMMU 多任务多模态理解测试 - 评估文本、图像、音频和视频的综合理解能力 | 81.7% 来源 |
HellaSwag 高难度句子补全基准测试 | 不可用 |
HumanEval 评估代码生成和问题解决能力 | 不可用 |
MATH 测试不同难度级别的数学问题解决能力 | 不可用 |
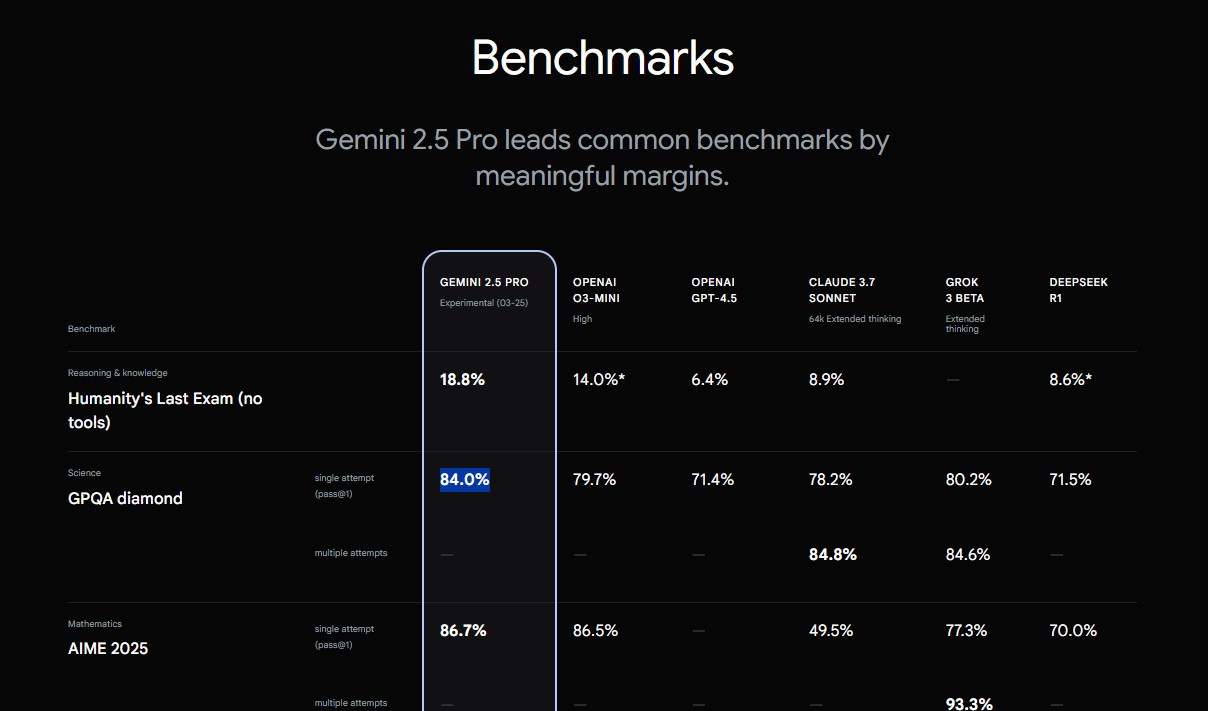
GPQA 通过需要深度专业知识的选择题测试化学、生物和物理领域的博士水平知识 | 84.0% Diamond Science 来源 |
IFEval 测试模型准确遵循格式指令、生成适当输出并在不同任务中保持指令一致性的能力 | 不可用 |
SimpleQA 评估简单问题的准确性 | 52.9% |
AIME 2024 | 92.0% |
AIME 2025 | 86.7% |
Aider Polyglot 多语言编程基准。 | 74.0% / 68.6% |
LiveCodeBench v5 实时编程基准测试 | 70.4% |
Global MMLU (Lite) 用于评估模型在全球层面通用性的简化基准测试。 | 89.8% |
MathVista 评估人工智能模型在视觉环境中的数学推理能力 | - |
移动应用 | |
VideoGameBench | |
| 总分 | 0.48% |
| Doom II | 0% |
| Dream DX | 4.8% |
| Awakening DX | 0% |
| Civilization I | 0% |
| Pokemon Crystal | 0% |
| The Need for Speed | 0% |
| The Incredible Machine | 0% |
| Secret Game 1 | 0% |
| Secret Game 2 | 0% |
| Secret Game 3 | 0% |
MathArena | |
| 平均分数 | 81% |
| AIME 2025 基于美国邀请数学考试(American Invitational Mathematics Examination)题目的测试,旨在检验模型的数学能力。 | 87% |
| HMMT February 2025 基于2025年2月哈佛-MIT数学竞赛题目的测试,旨在检验模型的数学能力。 | 82% |
| BRUMO 2025 | 90% |
| SMT 2025 基于2025年斯坦福数学竞赛题目的测试,旨在检验模型的数学能力。 | 85% |
| CMIMC 2025 基于2025年加拿大数学奥林匹克竞赛题目的测试,旨在检验模型的数学能力。 | 58% |
评论 (1)
Mazen
11 八月 2025Good program