


OpenAI o4-mini is het nieuwste lichtgewicht model in de o-serie, ontworpen voor efficiënte en capabele redenering over tekst- en visuele taken. Geoptimaliseerd voor snelheid en prestaties, blinkt het uit in codegeneratie en beeldbegrip, terwijl het een balans behoudt tussen latentie en redeneerdiepte. Het model ondersteunt een contextvenster van 200.000 tokens met maximaal 100.000 uitvoertokens, wat het geschikt maakt voor uitgebreide interacties met hoge volumes. Het verwerkt zowel tekst- als beeldinvoer en produceert tekstuele uitvoer met geavanceerde redeneermogelijkheden. Met zijn compacte architectuur en veelzijdige prestaties is o4-mini ideaal voor een breed scala aan real-world toepassingen die snelle en kosteneffectieve intelligentie vereisen.
Website AI Model Webpagina | |
Aanbieder De entiteit die dit model aanbiedt. | |
Chat Voer een bericht in om te beginnen met chatten | |
Releasedatum Wanneer het model voor het eerst is vrijgegeven. | 1 jaar ago Apr 16, 2025 |
Modaliteiten Soorten gegevens die dit model kan verwerken | tekst afbeeldingen |
API-Aanbieders De aanbieders die dit model leveren. (Dit is geen uitputtende lijst.) | OpenAI API |
Kennisafsluitdatum Wanneer de kennis van het model voor het laatst is bijgewerkt. | - |
Open Source Of de code van het model beschikbaar is voor publiek gebruik. | Nee |
Prijzen Invoer Kosten voor het verwerken van tokens in uw prompts | $1.10 per miljoen tokens |
Prijzen Uitvoer Kosten voor tokens gegenereerd door het model | $4.40 per miljoen tokens |
MMLU Massive Multitask Language Understanding - Test kennis over 57 onderwerpen, waaronder wiskunde, geschiedenis, recht en meer | fort |
MMLU-Pro Een robuustere MMLU-benchmark met moeilijkere, op redenering gerichte vragen, een grotere keuzeset en verminderde gevoeligheid voor prompts | - |
MMMU Massive Multitask Multimodal Understanding - Test begrip van tekst, afbeeldingen, audio en video | 81.6% Bron |
HellaSwag Een uitdagende benchmark voor zinsvoltooiing | - |
HumanEval Evalueert codegeneratie en probleemoplossende vaardigheden | 14.28% Bron |
MATH Test wiskundige probleemoplossende vaardigheden op verschillende moeilijkheidsniveaus | - |
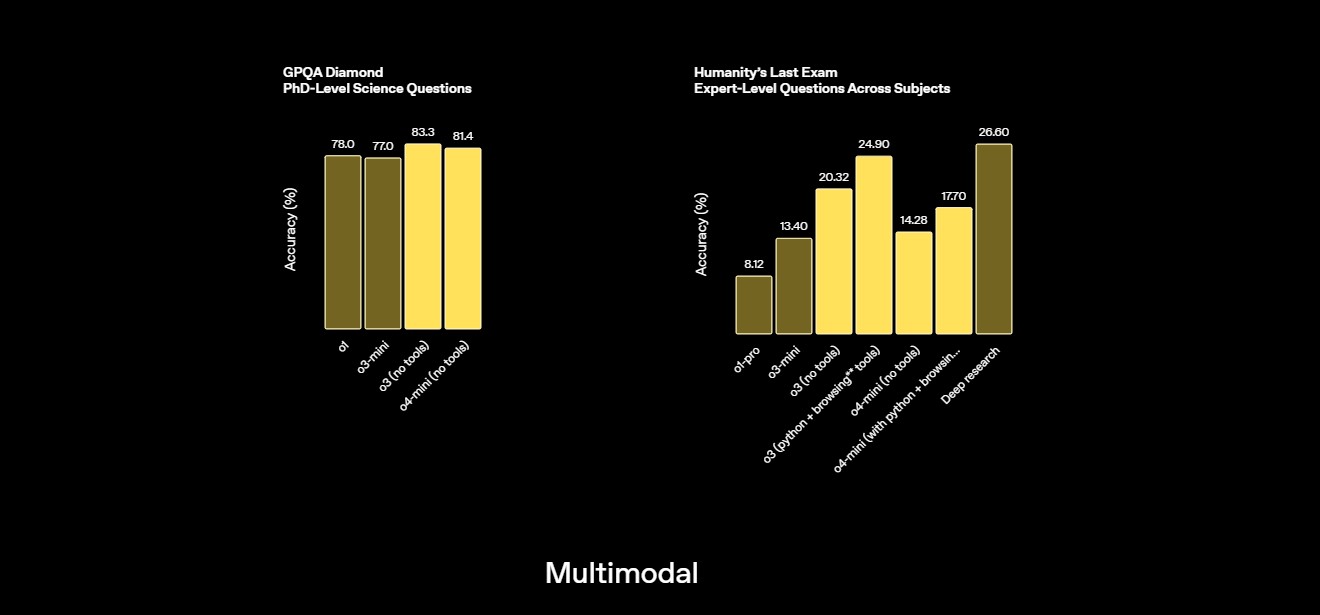
GPQA Test PhD-niveau kennis in scheikunde, biologie en natuurkunde door meerkeuzevragen die diepgaande domeinkennis vereisen | 81.4% Bron |
IFEval Test het vermogen van het model om expliciete opmaakinstructies nauwkeurig te volgen, geschikte uitvoer te genereren en consistente instructienaleving te behouden bij verschillende taken | - |
SimpleQA Evaluatie van de nauwkeurigheid van eenvoudige vragen | - |
AIME 2024 | 93.4% Bron |
AIME 2025 | 92.7% Bron |
Aider Polyglot Meertalige programmeerbenchmark. | - |
LiveCodeBench v5 Benchmark voor realtime programmeren | - |
Global MMLU (Lite) Een vereenvoudigde versie van de benchmark om de universaliteit van modellen op wereldwijd niveau te beoordelen. | - |
MathVista Evalueert de wiskundige redeneervermogens van AI-modellen binnen visuele contexten | - |
Mobiele applicatie | |
MathArena | |
| Gemiddelde score | 87% |
| AIME 2025 Test gebaseerd op opgaven uit de wiskundewedstrijd (American Invitational Mathematics Examination),bedoeld om de wiskundige vaardigheden van modellen te testen. | 92% |
| HMMT February 2025 Test gebaseerd op opgaven van het Harvard-MIT Mathematics Tournament, februari 2025, bedoeld om de wiskundige vaardigheden van modellen te testen. | 83% |
| BRUMO 2025 | 87% |
| SMT 2025 Test gebaseerd op opgaven van het Stanford Math Tournament, 2025, bedoeld om de wiskundige vaardigheden van modellen te testen. | 89% |
| CMIMC 2025 Test gebaseerd op opgaven van de Canadian Mathematical Olympiad, 2025, bedoeld om de wiskundige vaardigheden van modellen te testen. | 84% |
Compare AI. Test. Benchmarks. Mobiele Chatbot-apps, Sketch
Copyright © 2026 All Right Reserved.