


OpenAI o4-mini est le dernier modèle léger de la série o, conçu pour un raisonnement efficace et performant à travers les tâches textuelles et visuelles. Optimisé pour la vitesse et les performances, il excelle dans la génération de code et la compréhension basée sur les images, tout en maintenant un équilibre entre latence et profondeur de raisonnement. Le modèle prend en charge une fenêtre de contexte de 200 000 tokens avec jusqu'à 100 000 tokens en sortie, le rendant adapté aux interactions étendues et volumineuses. Il gère à la fois les entrées textuelles et visuelles, produisant des sorties textuelles avec des capacités de raisonnement avancées. Grâce à son architecture compacte et ses performances polyvalentes, o4-mini est idéal pour une large gamme d'applications réelles nécessitant une intelligence rapide et rentable.
Site web Page web du modèle d’IA | |
Fournisseur L’entité qui fournit ce modèle. | |
Chat Entrez un message pour commencer à discuter | |
Date de sortie Première date de publication du modèle. | 1 an ago Avr 16, 2025 |
Modalités Types de données que ce modèle peut traiter | texte images |
Fournisseurs d’API Les fournisseurs qui proposent ce modèle. (Cette liste n’est pas exhaustive.) | OpenAI API |
Date de mise à jour des connaissances Dernière mise à jour des connaissances du modèle. | - |
Open Source Disponibilité du code du modèle pour une utilisation publique. | Non |
Tarification d’entrée Coût du traitement des tokens dans vos invites | $1.10 par million de tokens |
Tarification de sortie Coût des tokens générés par le modèle | $4.40 par million de tokens |
MMLU Massive Multitask Language Understanding - Évalue les connaissances dans 57 domaines, y compris les mathématiques, l’histoire, le droit et plus encore | fort |
MMLU-Pro Un benchmark MMLU plus robuste avec des questions plus complexes axées sur le raisonnement, un plus grand ensemble de choix et une sensibilité réduite aux invites | - |
MMMU Massive Multitask Multimodal Understanding - Évalue la compréhension à travers le texte, les images, l’audio et la vidéo | 81.6% Source |
HellaSwag Un benchmark exigeant de complétion de phrases | - |
HumanEval Évalue la génération de code et les capacités de résolution de problèmes | 14.28% Source |
MATH Évalue les capacités de résolution de problèmes mathématiques à différents niveaux de difficulté | - |
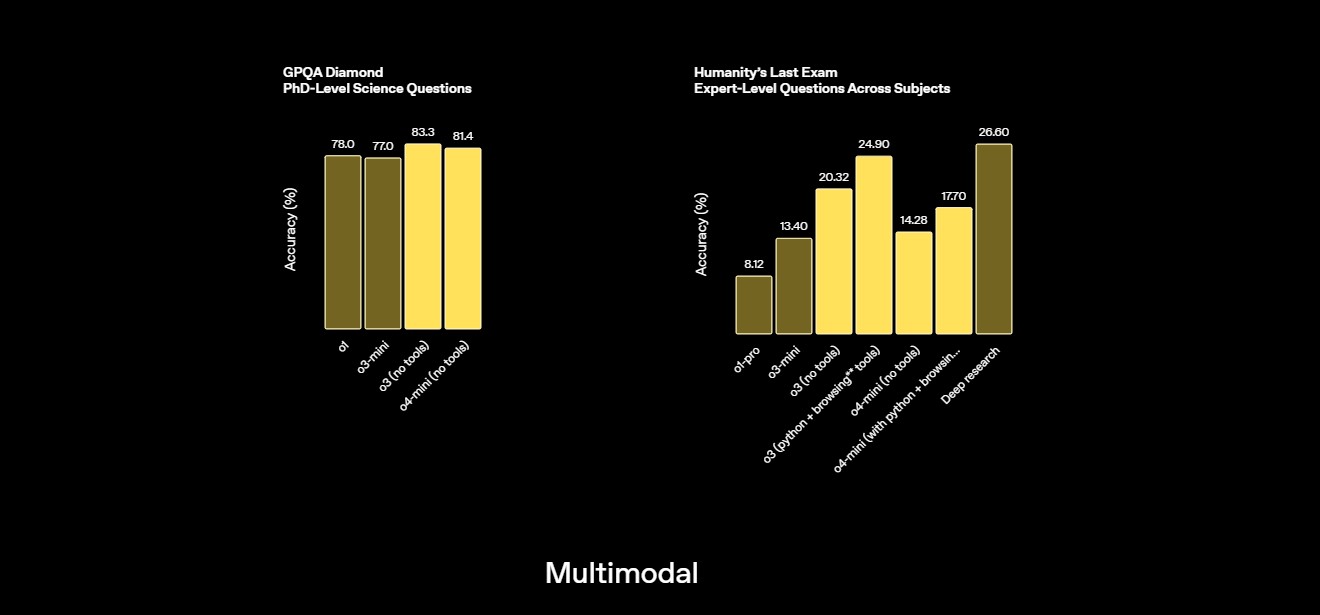
GPQA Évalue les connaissances de niveau doctorat en chimie, biologie et physique via des questions à choix multiples nécessitant une expertise approfondie | 81.4% Source |
IFEval Évalue la capacité du modèle à suivre avec précision des instructions de formatage explicites, à générer des sorties appropriées et à maintenir une cohérence dans l’exécution des tâches | - |
SimpleQA Évaluation de la précision des questions simples | - |
AIME 2024 | 93.4% Source |
AIME 2025 | 92.7% Source |
Aider Polyglot Benchmark de programmation multilingue. | - |
LiveCodeBench v5 Benchmark pour la programmation en temps réel | - |
Global MMLU (Lite) Une version simplifiée du benchmark pour évaluer l’universalité des modèles au niveau mondial. | - |
MathVista Évalue les capacités de raisonnement mathématique des modèles d’IA dans des contextes visuels | - |
Application mobile | |
MathArena | |
| Score moyen | 87% |
| AIME 2025 Test basé sur des problèmes issus du concours de mathématiques (American Invitational Mathematics Examination),destiné à évaluer les compétences mathématiques des modèles. | 92% |
| HMMT February 2025 Test basé sur des problèmes du Harvard-MIT Mathematics Tournament, février 2025, destiné à évaluer les compétences mathématiques des modèles. | 83% |
| BRUMO 2025 | 87% |
| SMT 2025 Test basé sur des problèmes du Stanford Math Tournament, 2025, destiné à évaluer les compétences mathématiques des modèles. | 89% |
| CMIMC 2025 Test basé sur des problèmes de l’Olympiade mathématique canadienne, 2025, destiné à évaluer les compétences mathématiques des modèles. | 84% |
Compare AI. Test. Benchmarks. Applications de chatbots mobiles, Sketch
Copyright © 2026 All Right Reserved.