


OpenAI o4-mini, o-serisinin en yeni hafif modeli olup, metin ve görsel görevlerde verimli ve yetenekli akıl yürütme için tasarlanmıştır. Hız ve performans açısından optimize edilmiş olup, kod üretimi ve görsel tabanlı anlayışta üstün başarı gösterirken gecikme süresi ile akıl yürütme derinliği arasında dengeli bir yapı sunar. Model, 200.000 token bağlam penceresini ve 100.000'e kadar çıktı token desteğini sağlayarak uzun ve yüksek hacimli etkileşimler için uygundur. Hem metin hem de görsel girdileri işleyerek gelişmiş akıl yürütme yetenekleriyle metinsel çıktılar üretir. Kompakt mimarisi ve çok yönlü performansı ile o4-mini, hızlı ve maliyet açısından verimli zekâ gerektiren geniş çaplı gerçek dünya uygulamaları için idealdir.
Web Sitesi Yapay Zeka Modeli Web Sayfası | |
Sağlayıcı Bu modeli sağlayan kuruluş. | |
Sohbet Sohbete başlamak için bir mesaj yazın | |
Yayın Tarihi Modelin ilk kez ne zaman yayınlandığı. | 1 yıl ago Nis 16, 2025 |
Modallikler Bu modelin işleyebileceği veri türleri | metin görseller |
API Sağlayıcıları Bu modeli sunan sağlayıcılar. (Bu liste tamamlayıcı değildir.) | OpenAI API |
Bilgi Kesim Tarihi Modelin bilgileri en son ne zaman güncellendi. | - |
Açık Kaynak Modelin kodunun kamuya açık olup olmadığı. | Hayır |
Fiyatlandırma Girdisi Komutlarınızdaki belirteçlerin işlenme maliyeti | $1.10 milyon belirteç başına |
Fiyatlandırma Çıktısı Model tarafından üretilen belirteçlerin maliyeti | $4.40 milyon belirteç başına |
MMLU Massive Multitask Language Understanding – Matematik, tarih, hukuk ve daha fazlası dahil 57 konuda bilgi testi | fort |
MMLU-Pro Daha zorlu, akıl yürütmeye odaklanan sorular, daha geniş seçenek seti ve azaltılmış yönlendirme hassasiyeti ile geliştirilmiş MMLU kıyaslaması | - |
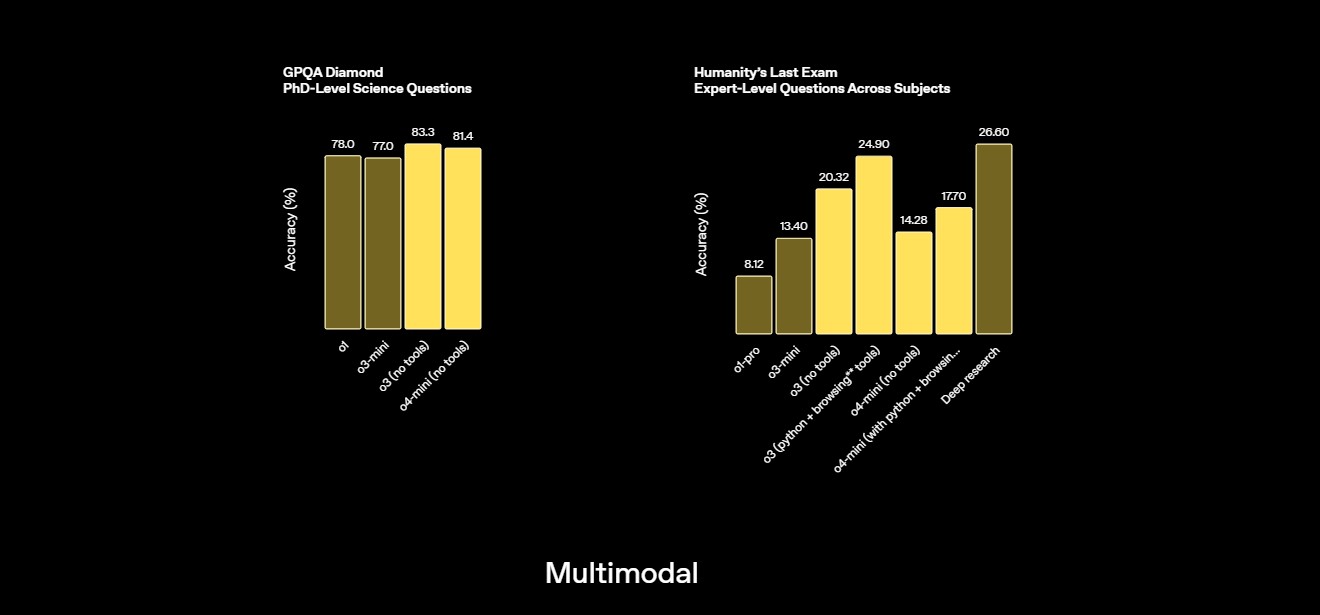
MMMU Massive Multitask Multimodal Understanding – Metin, görsel, ses ve video üzerinden anlama testi | 81.6% Kaynak |
HellaSwag Zorlu bir cümle tamamlama kıyaslaması | - |
HumanEval Kod üretimi ve problem çözme yeteneklerini değerlendirir | 14.28% Kaynak |
MATH Farklı zorluk seviyelerinde matematiksel problem çözme yeteneklerini test eder | - |
GPQA Kimya, biyoloji ve fizikte doktora düzeyindeki bilgiyi çoktan seçmeli sorularla test eder; derin alan uzmanlığı gerektirir | 81.4% Kaynak |
IFEval Modelin açık biçimlendirme talimatlarını doğru bir şekilde takip etme, uygun çıktılar üretme ve farklı görevlerde tutarlı talimat uyumu sağlama yeteneğini test eder | - |
SimpleQA Basit soruların doğruluğunu değerlendirme | - |
AIME 2024 | 93.4% Kaynak |
AIME 2025 | 92.7% Kaynak |
Aider Polyglot Çok dilli programlama karşılaştırma testi. | - |
LiveCodeBench v5 Gerçek zamanlı programlama karşılaştırma testi | - |
Global MMLU (Lite) Modellerin evrenselliğini küresel ölçekte değerlendirmek için sadeleştirilmiş karşılaştırma testi. | - |
MathVista Yapay zeka modellerinin görsel bağlamlardaki matematiksel akıl yürütme yetilerini değerlendirir | - |
Mobil Uygulama | |
MathArena | |
| Ortalama puan | 87% |
| AIME 2025 American Invitational Mathematics Examination sorularına dayalı test, modellerin matematik becerilerini değerlendirmek amacıyla hazırlanmıştır. | 92% |
| HMMT February 2025 Şubat 2025 Harvard-MIT Mathematics Tournament sorularına dayalı test, modellerin matematik becerilerini değerlendirmek amacıyla hazırlanmıştır. | 83% |
| BRUMO 2025 | 87% |
| SMT 2025 2025 Stanford Math Tournament sorularına dayalı test, modellerin matematik becerilerini değerlendirmek amacıyla hazırlanmıştır. | 89% |
| CMIMC 2025 2025 Canadian Mathematical Olympiad sorularına dayalı test, modellerin matematik becerilerini değerlendirmek amacıyla hazırlanmıştır. | 84% |
Compare AI. Test. Benchmarks. Mobil Uygulamalar Sohbet Botları, Sketch
Copyright © 2026 All Right Reserved.