


OpenAI o4-mini to najnowszy lekki model w serii o, zaprojektowany do wydajnego i skutecznego rozumowania w zadaniach tekstowych i wizualnych. Zoptymalizowany pod kątem szybkości i wydajności, wyróżnia się generowaniem kodu i zrozumieniem opartym na obrazach, zachowując równowagę między opóźnieniem a głębią rozumowania. Model obsługuje okno kontekstu o wielkości 200 000 tokenów z maksymalnie 100 000 tokenów wyjściowych, co czyni go odpowiednim do rozbudowanych interakcji o dużej objętości. Przetwarza zarówno dane tekstowe, jak i obrazowe, generując tekstowe wyniki z zaawansowanymi możliwościami rozumowania. Dzięki kompaktowej architekturze i wszechstronnej wydajności o4-mini jest idealny do szerokiego zakresu rzeczywistych zastosowań wymagających szybkiej i opłacalnej inteligencji.
Strona internetowa Strona internetowa modelu AI | |
Dostawca Podmiot dostarczający ten model. | |
Czat Wpisz wiadomość, aby rozpocząć czat | |
Data wydania Kiedy model został po raz pierwszy wydany. | 1 rok ago Kwi 16, 2025 |
Modalności Rodzaje danych, które ten model może przetwarzać | tekst obrazy |
Dostawcy API Dostawcy oferujący ten model. (To nie jest wyczerpująca lista.) | OpenAI API |
Data ostatniej aktualizacji wiedzy Kiedy wiedza modelu była ostatnio aktualizowana. | - |
Open Source Czy kod modelu jest dostępny do publicznego użytku. | Nie |
Cena za wejście Koszt przetwarzania tokenów w Twoich promptach | $1.10 za milion tokenów |
Cena za wyjście Koszt za tokeny wygenerowane przez model | $4.40 za milion tokenów |
MMLU Massive Multitask Language Understanding - Testuje wiedzę z 57 dziedzin, w tym matematyki, historii, prawa i innych | fort |
MMLU-Pro Bardziej zaawansowane benchmarki MMLU z trudniejszymi pytaniami skupionymi na rozumowaniu, większym zestawem wyborów i zmniejszoną wrażliwością na prompty | - |
MMMU Massive Multitask Multimodal Understanding - Testuje rozumienie tekstu, obrazów, dźwięku i wideo | 81.6% Źródło |
HellaSwag Wymagające benchmarki uzupełniania zdań | - |
HumanEval Ocenia możliwości generowania kodu i rozwiązywania problemów | 14.28% Źródło |
MATH Testuje umiejętności rozwiązywania problemów matematycznych na różnych poziomach trudności | - |
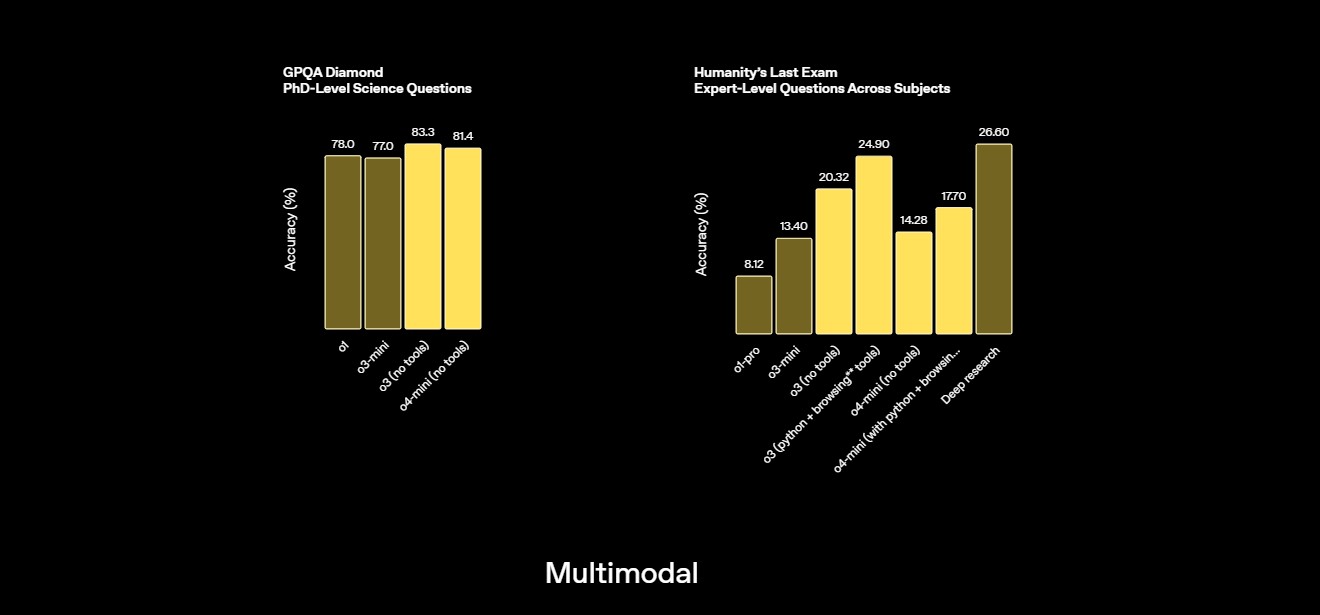
GPQA Testuje wiedzę na poziomie doktorskim z chemii, biologii i fizyki poprzez pytania wielokrotnego wyboru wymagające głębokiej wiedzy specjalistycznej | 81.4% Źródło |
IFEval Testuje zdolność modelu do dokładnego przestrzegania wyraźnych instrukcji formatowania, generowania odpowiednich wyników i utrzymania spójnego przestrzegania instrukcji w różnych zadaniach | - |
SimpleQA Ocena dokładności prostych pytań | - |
AIME 2024 | 93.4% Źródło |
AIME 2025 | 92.7% Źródło |
Aider Polyglot Wielojęzyczny benchmark programistyczny. | - |
LiveCodeBench v5 Benchmark programowania w czasie rzeczywistym | - |
Global MMLU (Lite) Uproszczona wersja benchmarku do oceny uniwersalności modeli na poziomie globalnym. | - |
MathVista Ocenia zdolności rozumowania matematycznego modeli AI w kontekstach wizualnych | - |
Aplikacja mobilna | |
MathArena | |
| Średni wynik | 87% |
| AIME 2025 Test oparty na zadaniach z konkursu matematycznego (American Invitational Mathematics Examination),mający na celu sprawdzenie umiejętności matematycznych modeli. | 92% |
| HMMT February 2025 Test oparty na zadaniach z Harvard-MIT Mathematics Tournament, luty 2025, mający na celu sprawdzenie umiejętności matematycznych modeli. | 83% |
| BRUMO 2025 | 87% |
| SMT 2025 Test oparty na zadaniach z Stanford Math Tournament, 2025, mający na celu sprawdzenie umiejętności matematycznych modeli. | 89% |
| CMIMC 2025 Test oparty na zadaniach z Canadian Mathematical Olympiad, 2025, mający na celu sprawdzenie umiejętności matematycznych modeli. | 84% |
Compare AI. Test. Benchmarks. Chatboty mobilne, Sketch
Copyright © 2026 All Right Reserved.