


El OpenAI o3-mini es un modelo de razonamiento rápido y rentable diseñado para aplicaciones STEM, con un alto rendimiento en ciencia, matemáticas y programación. Lanzado en enero de 2025, incluye funciones esenciales para desarrolladores, como llamadas a funciones, salidas estructuradas y mensajes para desarrolladores. El modelo ofrece tres niveles de esfuerzo de razonamiento—bajo, medio y alto—permitiendo a los usuarios optimizar entre un análisis más profundo y tiempos de respuesta más rápidos. A diferencia del modelo o3, carece de capacidades de visión. Inicialmente disponible para desarrolladores seleccionados en los niveles 3-5 de uso de la API, se puede acceder a través de la API de Chat Completions, la API de Assistants y la API de Batch.
Sitio Web Página Web del Modelo de IA | |
Proveedor La entidad que proporciona este modelo. | |
Chat Ingresa un mensaje para comenzar a chatear | - |
Fecha de Lanzamiento Cuándo se lanzó el modelo por primera vez. | 1 año ago Ene 31, 2025 |
Modalidades Tipos de datos que este modelo puede procesar | texto |
Proveedores de API Los proveedores que ofrecen este modelo. (Esta no es una lista exhaustiva). | OpenAI API |
Fecha de Corte de Conocimiento Cuándo se actualizó por última vez el conocimiento del modelo. | Desconocido |
Código Abierto Si el código del modelo está disponible para uso público. | No |
Costo de Entrada Costo por procesar tokens en tus solicitudes | $1.10 por millón de tokens |
Costo de Salida Costo por tokens generados por el modelo | $4.40 por millón de tokens |
MMLU Evaluación de Comprensión Multitarea Masiva - Pruebas de conocimiento en 57 disciplinas, incluyendo matemáticas, historia, derecho y más. | 86.9% pass@1, high effort Fuente |
MMLU-Pro Un criterio MMLU más avanzado con preguntas más difíciles enfocadas en el razonamiento, un mayor conjunto de opciones y menor sensibilidad a los prompts. | No disponible |
MMMU Evaluación de Comprensión Multitarea Multimodal - Pruebas de comprensión en texto, imágenes, audio y video. | No disponible |
HellaSwag Un exigente criterio de evaluación para completar oraciones. | No disponible |
HumanEval Evalúa la generación de código y habilidades de resolución de problemas. | No disponible |
MATH Pruebas de resolución de problemas matemáticos en distintos niveles de dificultad. | 97.9% pass@1, high effort Fuente |
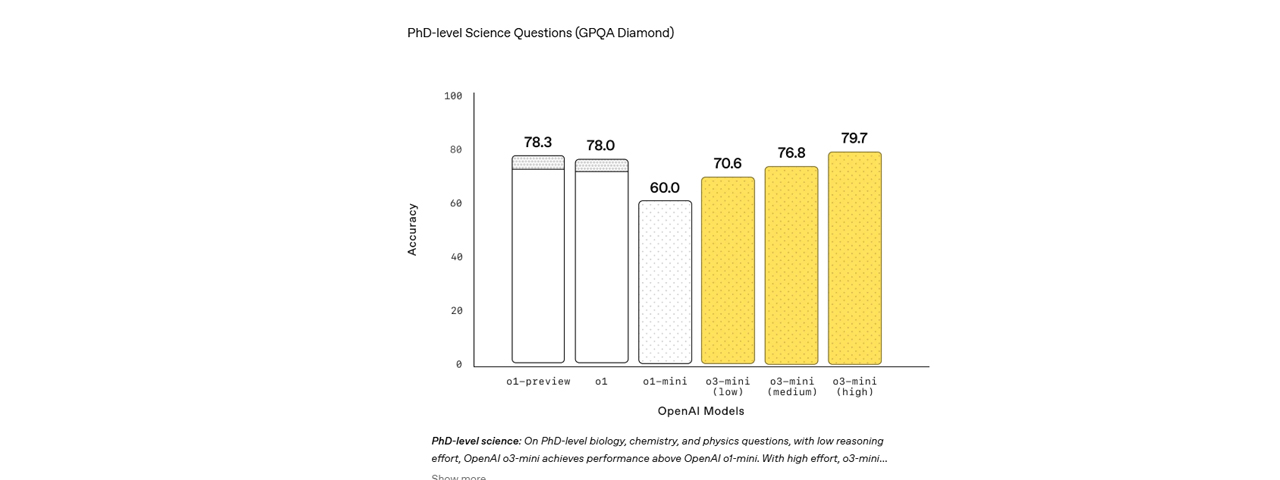
GPQA Evalúa conocimientos a nivel de doctorado en química, biología y física mediante preguntas de opción múltiple que requieren una comprensión profunda del dominio. | 79.7% 0-shot, high effort Fuente |
IFEval Evalúa la capacidad del modelo para seguir instrucciones de formato explícitas, generar respuestas adecuadas y mantener la coherencia en diversas tareas. | No disponible |
SimpleQA Evaluación de la precisión de preguntas simples | - |
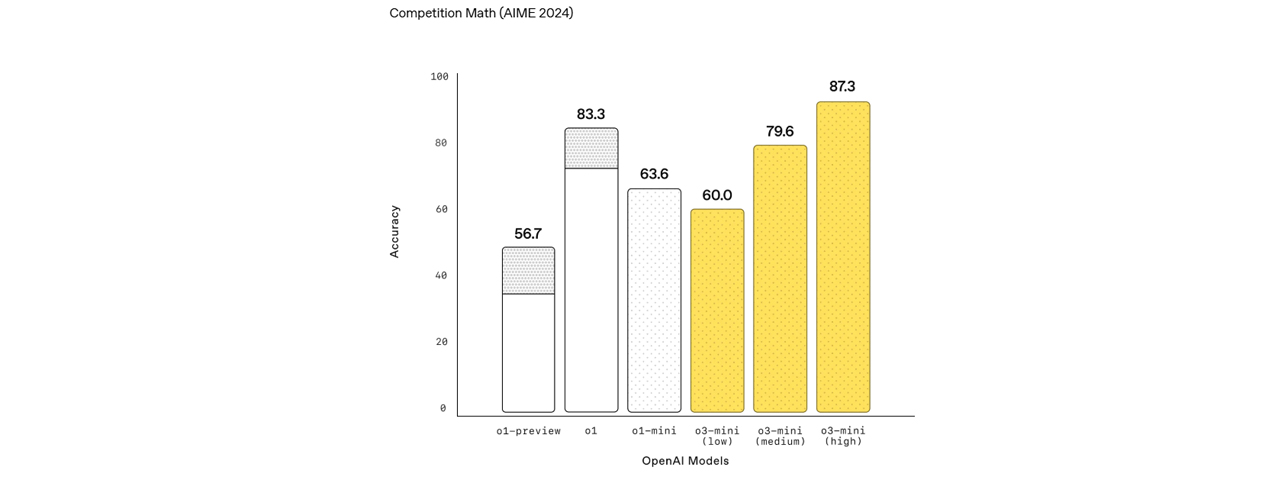
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot Benchmark de programación multilingüe. | - |
LiveCodeBench v5 Benchmark para programación en tiempo real | - |
Global MMLU (Lite) Una versión simplificada del benchmark para evaluar la universalidad de los modelos a nivel global. | - |
MathVista Evalúa las habilidades de razonamiento matemático de los modelos de IA dentro de contextos visuales | - |
Aplicación Móvil |
Compare AI. Test. Benchmarks. Chatbots Móviles, Sketch
Copyright © 2026 All Right Reserved.