


Das OpenAI o3-mini ist ein leistungsstarkes und kosteneffizientes Modell für schnelles logisches Denken, das speziell für MINT-Anwendungen entwickelt wurde und hervorragende Leistungen in Wissenschaft, Mathematik und Programmierung bietet. Es wurde im Januar 2025 veröffentlicht und enthält essenzielle Entwicklerfunktionen wie Funktionsaufrufe, strukturierte Ausgaben und Entwicklernachrichten. Das Modell verfügt über drei Stufen der Denkintensität—niedrig, mittel und hoch—damit Nutzer zwischen tiefgehender Analyse und schnelleren Antwortzeiten optimieren können. Im Gegensatz zum o3-Modell besitzt es keine visuellen Fähigkeiten. Zunächst ist es für ausgewählte Entwickler in den API-Stufen 3-5 verfügbar und kann über die Chat Completions API, Assistants API und Batch API genutzt werden.
Webseite KI-Modell-Webseite | |
Anbieter Die Entität, die dieses Modell bereitstellt. | |
Chat Geben Sie eine Nachricht ein, um zu chatten | - |
Veröffentlichungsdatum Wann das Modell erstmals veröffentlicht wurde. | 1 Jahr ago Jan 31, 2025 |
Modalitäten Arten von Daten, die dieses Modell verarbeiten kann | Text |
API-Anbieter Die Anbieter, die dieses Modell anbieten. (Diese Liste ist nicht vollständig.) | OpenAI API |
Datum des Wissensstandes Wann das Wissen des Modells zuletzt aktualisiert wurde. | Unbekannt |
Open Source Ob der Code des Modells öffentlich verfügbar ist. | Nein |
Preisgestaltung Eingabe Kosten für die Verarbeitung von Token in Ihren Eingaben | $1.10 pro Million Token |
Preisgestaltung Ausgabe Kosten für vom Modell generierte Token | $4.40 pro Million Token |
MMLU Massive Multitask Language Understanding – Testet Wissen in 57 Fächern, darunter Mathematik, Geschichte, Recht und mehr | 86.9% pass@1, high effort Quelle |
MMLU-Pro Ein robusterer MMLU-Benchmark mit schwierigeren, auf logisches Denken fokussierten Fragen, einer größeren Auswahl an Antworten und geringerer Sensitivität für Eingabevariationen | Nicht verfügbar |
MMMU Massive Multitask Multimodal Understanding – Testet das Verständnis über Text, Bilder, Audio und Video hinweg | Nicht verfügbar |
HellaSwag Ein anspruchsvoller Benchmark für Satzvervollständigung | Nicht verfügbar |
HumanEval Bewertet Codegenerierung und Problemlösungsfähigkeiten | Nicht verfügbar |
MATH Testet mathematische Problemlösungsfähigkeiten auf verschiedenen Schwierigkeitsstufen | 97.9% pass@1, high effort Quelle |
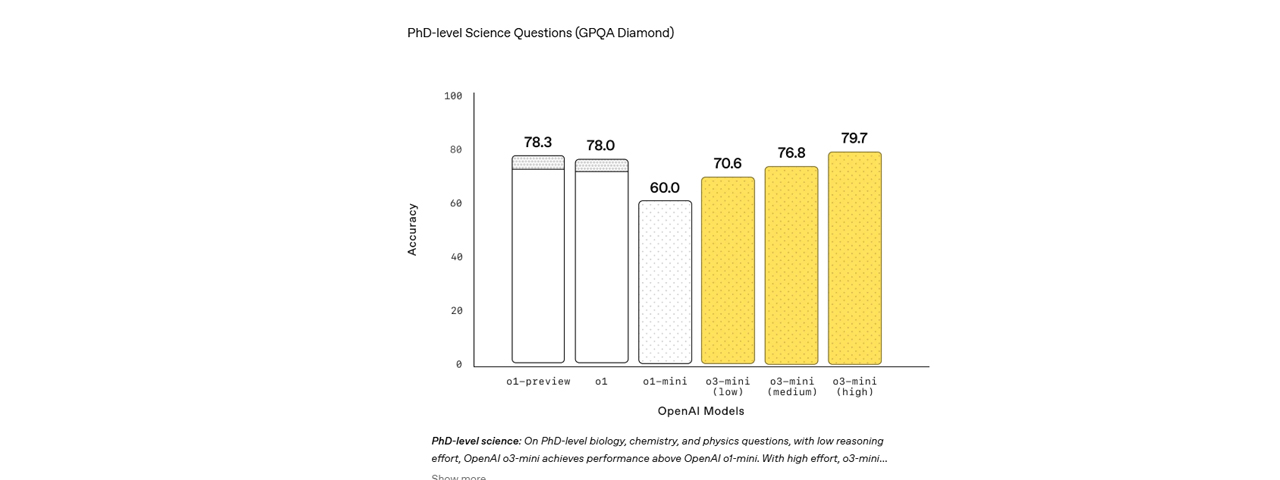
GPQA Testet Wissen auf PhD-Niveau in Chemie, Biologie und Physik durch Multiple-Choice-Fragen, die tiefgehendes Fachwissen erfordern | 79.7% 0-shot, high effort Quelle |
IFEval Testet die Fähigkeit des Modells, Formatierungsvorgaben genau zu befolgen, angemessene Ausgaben zu generieren und konsistente Instruktionsbefolgung über verschiedene Aufgaben hinweg zu gewährleisten | Nicht verfügbar |
SimpleQA Bewertung der Genauigkeit einfacher Fragen | - |
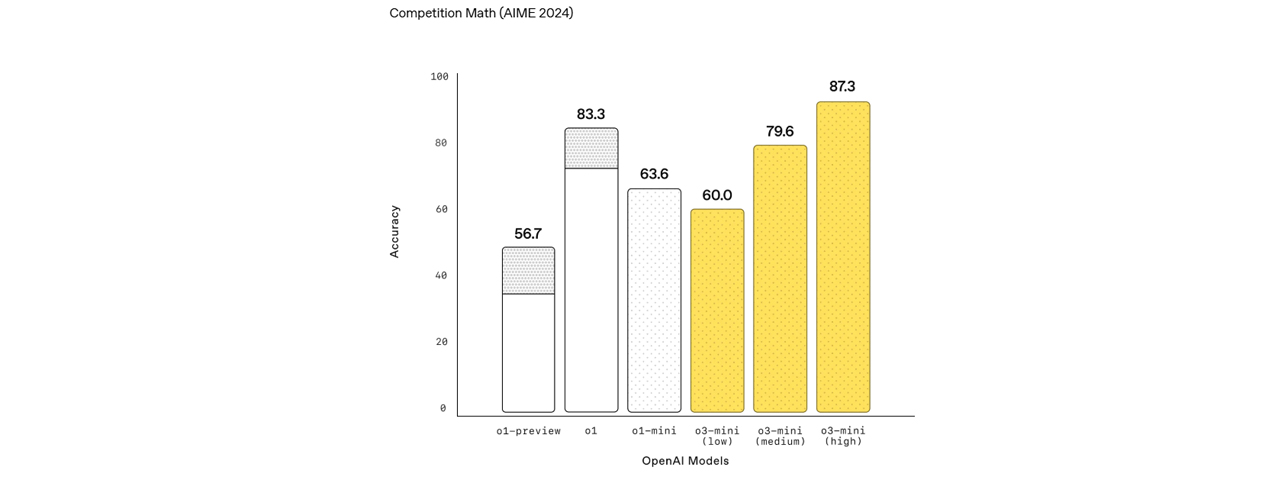
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot Mehrsprachige Programmier-Benchmark. | - |
LiveCodeBench v5 Benchmark für Echtzeit-Programmierung | - |
Global MMLU (Lite) Eine vereinfachte Version des Benchmarks zur Beurteilung der Universalität von Modellen auf globaler Ebene. | - |
MathVista Bewertet die mathematischen Denkfähigkeiten von KI-Modellen in visuellen Kontexten | - |
Mobile Anwendung |
Compare AI. Test. Benchmarks. Mobile Chatbot-Apps, Sketch
Copyright © 2026 All Right Reserved.