



كلود 3.5 هايكو، المطور من قبل أنثروبيك، يوفر نافذة سياقية تبلغ 200 ألف وحدة. يتم تحديد التسعير عند 1 دولار لكل مليون وحدة إدخال و5 دولارات لكل مليون وحدة إخراج، مع توفير محتمل يصل إلى 90٪ عبر التخزين المؤقت للطلبات و50٪ عبر واجهة Message Batches API. تم إصداره في 4 نوفمبر 2024، ويتفوق هذا النموذج في إكمال الأكواد، والدردشات التفاعلية، واستخراج البيانات وتصنيفها، بالإضافة إلى مراقبة المحتوى في الوقت الفعلي.
موقع الويب صفحة نموذج الذكاء الاصطناعي على الويب | |
المزود الكيان الذي يوفر هذا النموذج. | |
الدردشة أدخل رسالة لبدء الدردشة | - |
تاريخ الإصدار تاريخ الإصدار الأول للنموذج. | 1 سنة ago نوف 04, 2024 |
الوسائط أنواع البيانات التي يمكن لهذا النموذج معالجتها | نص |
مزودو API المزودون الذين يقدمون هذا النموذج. (هذه ليست قائمة شاملة.) | Anthropic, AWS Bedrock, Vertex AI |
تاريخ قطع المعرفة تاريخ آخر تحديث لمعرفة النموذج. | 01.04.2024 |
مفتوح المصدر ما إذا كان كود النموذج متاحًا للاستخدام العام. | لا |
تسعير الإدخال تكلفة معالجة الرموز في مطالباتك | $0.80 لكل مليون رمز |
تسعير الإخراج تكلفة الرموز التي يولدها النموذج | $4.00 |
MMLU فهم اللغة متعدد المهام الضخم - يختبر المعرفة عبر 57 موضوعًا بما في ذلك الرياضيات والتاريخ والقانون والمزيد | غير متاح |
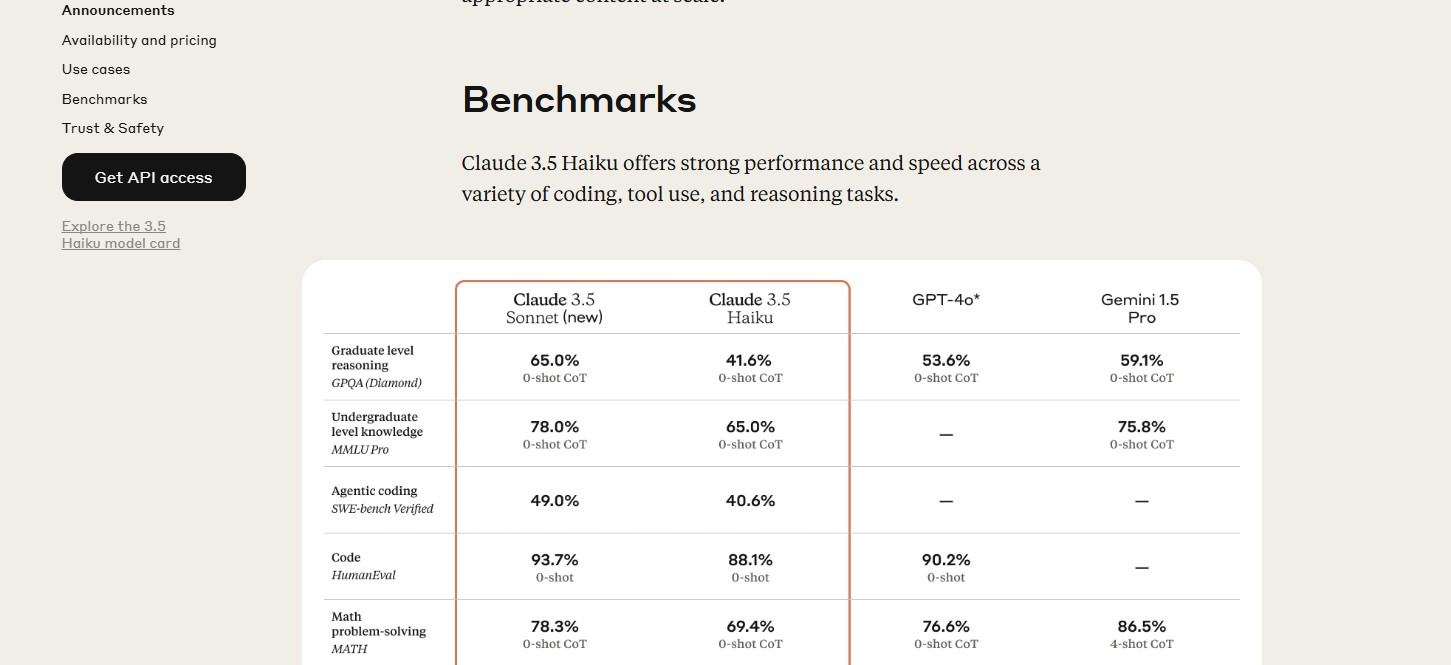
MMLU-Pro معيار MMLU أكثر قوة مع أسئلة أكثر صعوبة تركز على التفكير، ومجموعة اختيار أكبر، وتقليل حساسية المطالبة | 65% 0-shot CoT المصدر |
MMMU فهم متعدد المهام والوسائط الضخم - يختبر الفهم عبر النصوص والصور والصوت والفيديو | غير متاح |
HellaSwag معيار إكمال الجمل الصعب | غير متاح |
HumanEval يقيم قدرات توليد الكود وحل المشكلات | 88.1% 0-shot المصدر |
MATH يختبر قدرات حل المشكلات الرياضية عبر مستويات صعوبة مختلفة | 69.4% 0-shot CoT المصدر |
GPQA يختبر المعرفة على مستوى الدكتوراه في الكيمياء والأحياء والفيزياء من خلال أسئلة متعددة الخيارات تتطلب خبرة عميقة في المجال | غير متاح |
IFEval يختبر قدرة النموذج على اتباع تعليمات التنسيق الصريحة بدقة، وتوليد مخرجات مناسبة، والحفاظ على الالتزام بالتعليمات عبر مهام مختلفة | غير متاح |
SimpleQA تقييم دقة الأسئلة البسيطة | - |
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot معيار البرمجة متعدد اللغات. | - |
LiveCodeBench v5 معيار للبرمجة في الوقت الحقيقي | - |
Global MMLU (Lite) نسخة مبسطة من المعيار لتقييم عالمية النماذج على المستوى العالمي. | - |
MathVista تقييم قدرات التفكير الرياضي لنماذج الذكاء الاصطناعي في سياقات بصرية | - |
تطبيق الجوال |
Compare AI. Test. Benchmarks. تطبيبات دردشة الجوال, Sketch
Copyright © 2026 All Right Reserved.