
Az OpenAI o3 az OpenAI legfejlettebb gondolkodási modellje, amelyet kifejezetten összetett, magas kognitív igényű feladatok kezelésére terveztek. 2025 áprilisában jelent meg, kiváló teljesítményt nyújtva a szoftverfejlesztésben, matematikában és tudományos problémamegoldásban. A modell három szintű gondolkodási erőfeszítést vezet be – alacsony, közepes és magas –, lehetővé téve a felhasználók számára, hogy a feladat összetettsége alapján mérlegeljenek a késleltetés és a gondolkodás mélysége között. Az o3 támogatja a fejlesztők számára nélkülözhetetlen eszközöket, beleértve a függvényhívásokat, strukturált kimeneteket és rendszerszintű üzeneteket. Beépített látási képességekkel az o3 képes képeket értelmezni és elemezni, ami multimodális alkalmazásokhoz teszi alkalmassá. Elérhető a Chat Completions API, az Assistants API és a Batch API segítségével, rugalmas integrációt biztosítva vállalati és kutatási munkafolyamatokba.
Weboldal AI Modell Weboldal | |
Szolgáltató A modellt biztosító entitás. | |
Csevegés Írjon be egy üzenetet a csevegés megkezdéséhez | |
Kiadási Dátum Mikor jelent meg a modell először. | 1 év ago Ápr 16, 2025 |
Modalitások A modell által feldolgozható adattípusok | szöveg képek |
API Szolgáltatók A modellt kínáló szolgáltatók. (Ez nem egy teljes lista.) | OpenAI API |
Tudás Befejezési Dátuma Utoljára mikor frissült a modell tudása. | - |
Nyílt Forráskódú A modell kódja nyilvánosan használható-e. | Nem |
Bemeneti Árazás A promptokban feldolgozott tokenek költsége | $10.00 millió tokenenként |
Kimeneti Árazás A modell által generált tokenek költsége | $40.00 millió tokenenként |
MMLU Massive Multitask Language Understanding – 57 tantárgyban teszteli a tudást, beleértve a matematikát, történelmet, jogot és egyebeket | 82.9% Forrás |
MMLU-Pro Egy robusztusabb MMLU benchmark nehezebb, gondolkodásra összpontosító kérdésekkel, nagyobb választási lehetőségekkel és csökkentett prompt érzékenységgel | - |
MMMU Massive Multitask Multimodal Understanding – Teszteli a megértést szöveg, kép, hang és videó terén | - |
HellaSwag Egy kihívást jelentő mondatkiegészítési benchmark | - |
HumanEval Értékeli a kódgenerálás és problémamegoldó képességeket | - |
MATH Különböző nehézségi szinteken teszteli a matematikai problémamegoldó képességeket | - |
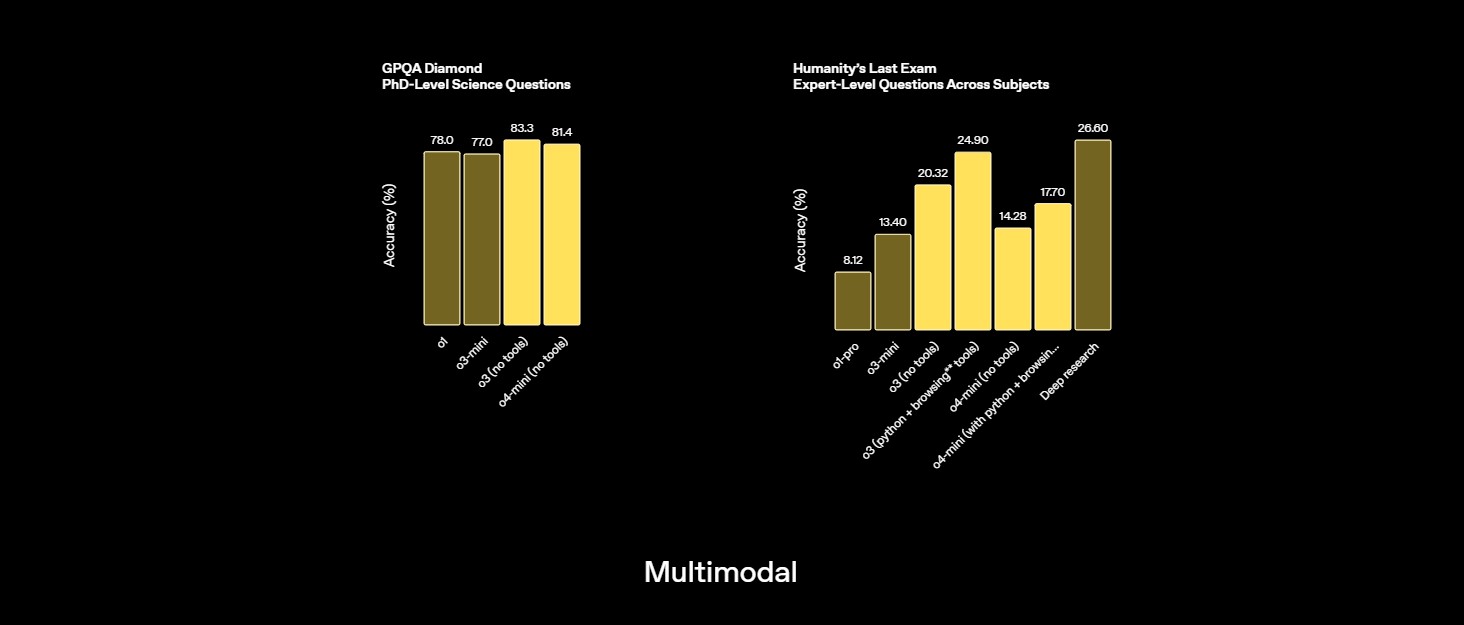
GPQA Doktori szintű tudást tesztel kémiában, biológiában és fizikában, több választós kérdéseken keresztül, amelyek mély szakmai tudást igényelnek | 83.3% Diamond, no tools Forrás |
IFEval Teszteli a modell képességét, hogy pontosan kövesse az explicit formázási utasításokat, megfelelő kimeneteket generáljon, és következetesen betartsa az utasításokat különböző feladatok során | - |
SimpleQA Egyszerű kérdések pontosságának értékelése | - |
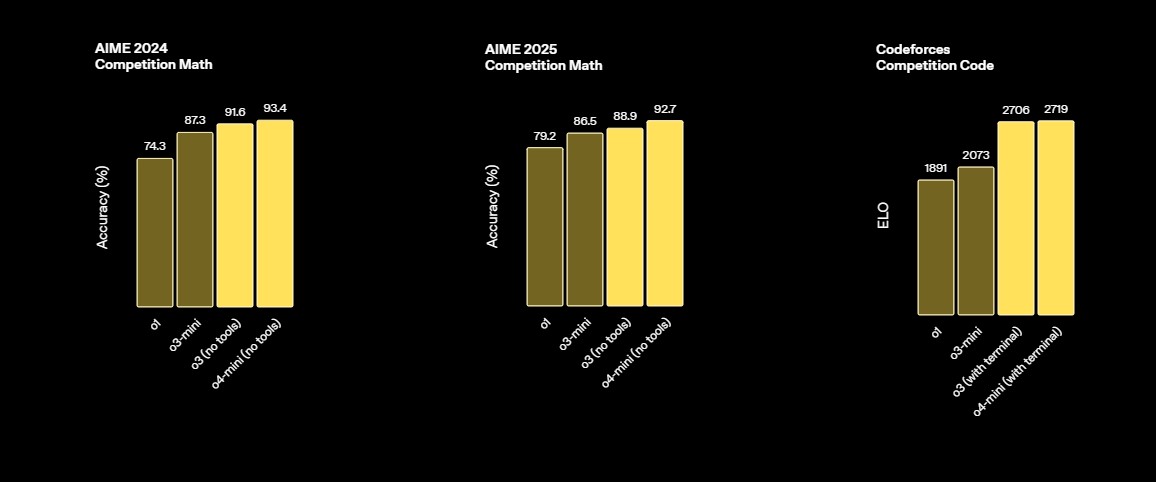
AIME 2024 | 91.6% Forrás |
AIME 2025 | 88.9% Forrás |
Aider Polyglot Többnyelvű programozási benchmark. | - |
LiveCodeBench v5 Valós idejű programozási benchmark | - |
Global MMLU (Lite) A benchmark egyszerűsített verziója a modellek globális szintű univerzalitásának értékelésére. | - |
MathVista Értékeli az AI modellek matematikai következtetési képességeit vizuális környezetben | - |
Mobilalkalmazás | |
MathArena | |
| Átlagpontszám | 86% |
| AIME 2025 Teszt, amely az American Invitational Mathematics Examination verseny feladataira épül, és a modellek matematikai készségeinek ellenőrzésére szolgál. | 89% |
| HMMT February 2025 Teszt, amely a Harvard-MIT Mathematics Tournament 2025. februári feladataira épül, és a modellek matematikai készségeinek ellenőrzésére szolgál. | 78% |
| BRUMO 2025 | 96% |
| SMT 2025 Teszt, amely a Stanford Math Tournament 2025. évi feladataira épül, és a modellek matematikai készségeinek ellenőrzésére szolgál. | 88% |
| CMIMC 2025 Teszt, amely a Canadian Mathematical Olympiad 2025. évi feladataira épül, és a modellek matematikai készségeinek ellenőrzésére szolgál. | 78% |
Compare AI. Test. Benchmarks. Mobil Chatbot Alkalmazások, Sketch
Copyright © 2026 All Right Reserved.