
OpenAI o3 je najpokročilejší model na uvažovanie od OpenAI, špeciálne vytvorený pre zvládanie zložitých úloh s vysokými kognitívnymi nárokmi. Spustený v apríli 2025 poskytuje výnimočný výkon v softvérovom inžinierstve, matematike a vedeckom riešení problémov. Model zavádza tri úrovne úsilia uvažovania – nízke, stredné a vysoké – čo umožňuje používateľom vyvážiť latenciu a hĺbku uvažovania podľa zložitosti úlohy. o3 podporuje základné nástroje pre vývojárov, vrátane volania funkcií, štruktúrovaných výstupov a systémových správ. S vstavanými vizuálnymi schopnosťami dokáže o3 interpretovať a analyzovať obrázky, čo ho robí vhodným pre multimodálne aplikácie. Je dostupný cez Chat Completions API, Assistants API a Batch API pre flexibilnú integráciu do podnikových a výskumných pracovných postupov.
Webová stránka Webová stránka AI modelu | |
Poskytovateľ Subjekt, ktorý poskytuje tento model. | |
Chat Zadajte správu a začnite chatovať | |
Dátum vydania Kedy bol model prvýkrát vydaný. | 1 rok ago Apr 16, 2025 |
Modality Typy dát, ktoré tento model dokáže spracovať | text obrázky |
Poskytovatelia API Poskytovatelia, ktorí ponúkajú tento model. (Toto nie je vyčerpávajúci zoznam.) | OpenAI API |
Dátum zastarania vedomostí Kedy boli vedomosti modelu naposledy aktualizované. | - |
Open Source Či je kód modelu dostupný na verejné použitie. | Nie |
Cena za vstup Cena za spracovanie tokenov vo vašich promptoch | $10.00 za milión tokenov |
Cena za výstup Cena za tokeny generované modelom | $40.00 za milión tokenov |
MMLU Massive Multitask Language Understanding – Testuje vedomosti v 57 predmetoch vrátane matematiky, histórie, práva a ďalších | 82.9% Zdroj |
MMLU-Pro Robustnejší benchmark MMLU s náročnejšími otázkami zameranými na uvažovanie, väčším výberom a zníženou citlivosťou na prompty | - |
MMMU Massive Multitask Multimodal Understanding – Testuje porozumenie textu, obrázkom, audiu a videu | - |
HellaSwag Náročný benchmark na dokončovanie viet | - |
HumanEval Hodnotí schopnosti generovania kódu a riešenia problémov | - |
MATH Testuje schopnosti riešenia matematických problémov na rôznych úrovniach náročnosti | - |
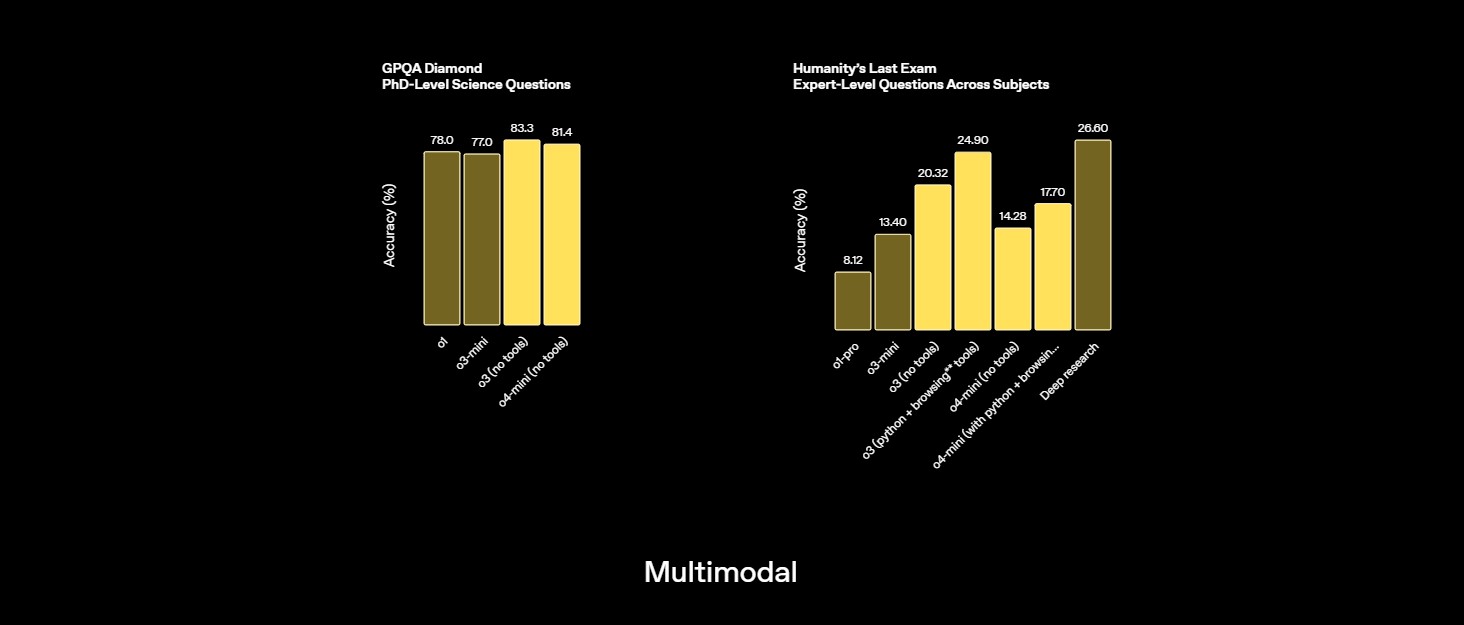
GPQA Testuje vedomosti na úrovni PhD v chémii, biológii a fyzike prostredníctvom otázok s výberom odpovedí, ktoré vyžadujú hlboké odborné znalosti | 83.3% Diamond, no tools Zdroj |
IFEval Testuje schopnosť modelu presne dodržiavať explicitné pokyny na formátovanie, generovať vhodné výstupy a udržiavať konzistentné dodržiavanie pokynov pri rôznych úlohách | - |
SimpleQA Hodnotenie presnosti jednoduchých otázok | - |
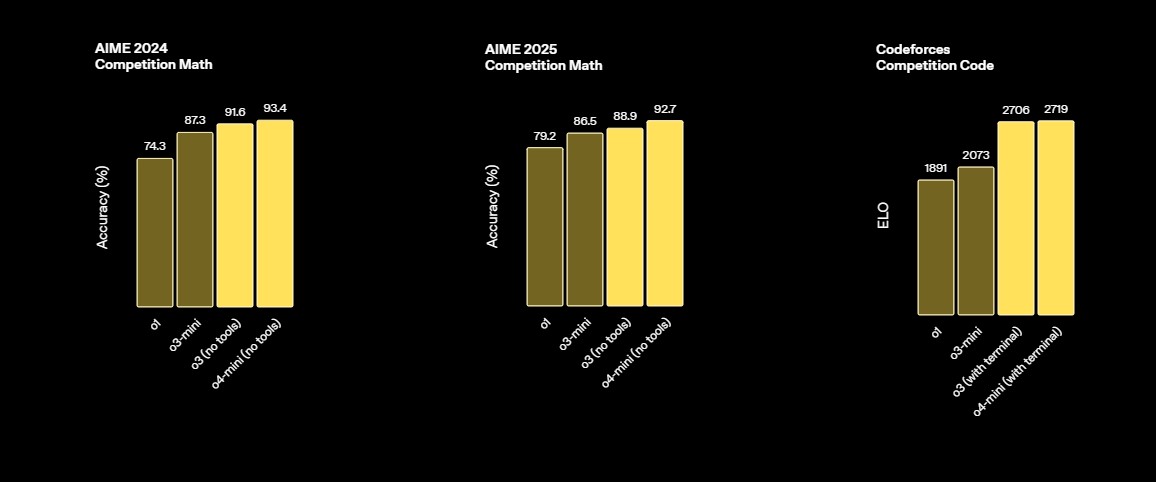
AIME 2024 | 91.6% Zdroj |
AIME 2025 | 88.9% Zdroj |
Aider Polyglot Viacjazyčný programovací benchmark. | - |
LiveCodeBench v5 Benchmark pre programovanie v reálnom čase | - |
Global MMLU (Lite) Zjednodušená verzia benchmarku na hodnotenie univerzálnosti modelov na globálnej úrovni. | - |
MathVista Hodnotí schopnosti matematického uvažovania modelov AI vo vizuálnych kontextoch | - |
Mobilná aplikácia | |
MathArena | |
| Priemerné skóre | 86% |
| AIME 2025 Test založený na úlohách zo súťaže v matematike (American Invitational Mathematics Examination),určený na overenie matematických schopností modelov. | 89% |
| HMMT February 2025 Test založený na úlohách z Harvard-MIT Mathematics Tournament, február 2025, určený na overenie matematických schopností modelov. | 78% |
| BRUMO 2025 | 96% |
| SMT 2025 Test založený na úlohách zo Stanford Math Tournament, 2025, určený na overenie matematických schopností modelov. | 88% |
| CMIMC 2025 Test založený na úlohách z Canadian Mathematical Olympiad, 2025, určený na overenie matematických schopností modelov. | 78% |
Compare AI. Test. Benchmarks. Chatboty pre mobilné aplikácie, Sketch
Copyright © 2026 All Right Reserved.