
Site web Page web du modèle d’IA | |
Fournisseur L’entité qui fournit ce modèle. | |
Chat Entrez un message pour commencer à discuter | |
Date de sortie Première date de publication du modèle. | 9 mois ago Aoû 05, 2025 |
Modalités Types de données que ce modèle peut traiter | texte |
Fournisseurs d’API Les fournisseurs qui proposent ce modèle. (Cette liste n’est pas exhaustive.) | Self-hosted, Hugging Face, AWS, Azure, Databricks |
Date de mise à jour des connaissances Dernière mise à jour des connaissances du modèle. | - |
Open Source Disponibilité du code du modèle pour une utilisation publique. | Oui |
Tarification d’entrée Coût du traitement des tokens dans vos invites | $0.15 par million de tokens |
Tarification de sortie Coût des tokens générés par le modèle | $0.60 par million de tokens |
MMLU Massive Multitask Language Understanding - Évalue les connaissances dans 57 domaines, y compris les mathématiques, l’histoire, le droit et plus encore | 82.7% Source |
MMLU-Pro Un benchmark MMLU plus robuste avec des questions plus complexes axées sur le raisonnement, un plus grand ensemble de choix et une sensibilité réduite aux invites | - |
MMMU Massive Multitask Multimodal Understanding - Évalue la compréhension à travers le texte, les images, l’audio et la vidéo | - |
HellaSwag Un benchmark exigeant de complétion de phrases | - |
HumanEval Évalue la génération de code et les capacités de résolution de problèmes | - |
MATH Évalue les capacités de résolution de problèmes mathématiques à différents niveaux de difficulté | - |
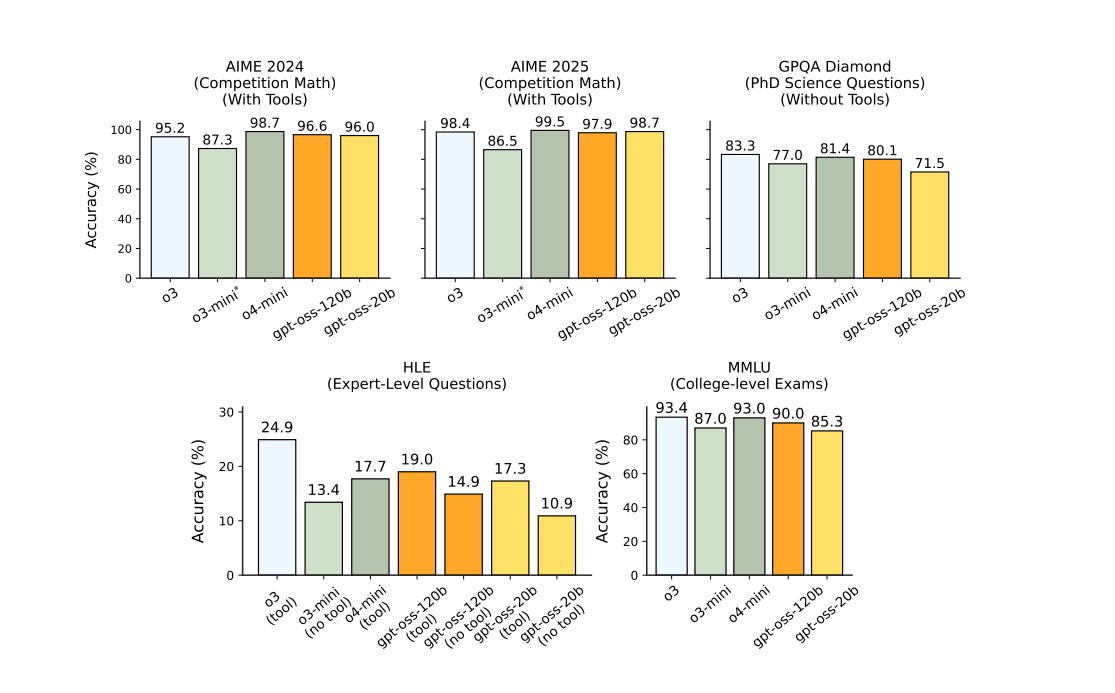
GPQA Évalue les connaissances de niveau doctorat en chimie, biologie et physique via des questions à choix multiples nécessitant une expertise approfondie | 80.1% Diamond Source |
IFEval Évalue la capacité du modèle à suivre avec précision des instructions de formatage explicites, à générer des sorties appropriées et à maintenir une cohérence dans l’exécution des tâches | - |
SimpleQA Évaluation de la précision des questions simples | 66.2% Source |
AIME 2024 | 69% Source |
AIME 2025 | 98.7% |
Aider Polyglot Benchmark de programmation multilingue. | - |
LiveCodeBench v5 Benchmark pour la programmation en temps réel | 42.7% v5 Source |
Global MMLU (Lite) Une version simplifiée du benchmark pour évaluer l’universalité des modèles au niveau mondial. | - |
MathVista Évalue les capacités de raisonnement mathématique des modèles d’IA dans des contextes visuels | - |
Application mobile | - |
Compare AI. Test. Benchmarks. Applications de chatbots mobiles, Sketch
Copyright © 2026 All Right Reserved.