
웹사이트 AI 모델 웹페이지 | |
제공자 이 모델을 제공하는 주체. | |
채팅 채팅을 시작하려면 메시지를 입력하세요 | |
출시일 모델이 처음 출시된 날짜. | 9 개월 ago 8월 05, 2025 |
모달리티 이 모델이 처리할 수 있는 데이터 유형 | 텍스트 |
API 제공자 이 모델을 제공하는 업체들. (전체 목록이 아님) | Self-hosted, Hugging Face, AWS, Azure, Databricks |
지식 업데이트 종료일 모델의 지식이 마지막으로 업데이트된 날짜. | - |
오픈 소스 모델 코드가 공개적으로 사용 가능한지 여부. | 예 |
입력 가격 프롬프트 토큰 처리 비용 | $0.15 100만 토큰당 |
출력 가격 모델이 생성한 토큰 비용 | $0.60 100만 토큰당 |
MMLU Massive Multitask Language Understanding - 수학, 역사, 법학 등 57개 과목에 걸친 지식 테스트 | 82.7% 출처 |
MMLU-Pro 더 어렵고 추론 중심의 질문, 더 큰 선택지, 프롬프트 민감도 감소로 강화된 MMLU 벤치마크 | - |
MMMU Massive Multitask Multimodal Understanding - 텍스트, 이미지, 오디오, 비디오에 걸친 이해력 테스트 | - |
HellaSwag 도전적인 문장 완성 벤치마크 | - |
HumanEval 코드 생성 및 문제 해결 능력 평가 | - |
MATH 다양한 난이도의 수학 문제 해결 능력 테스트 | - |
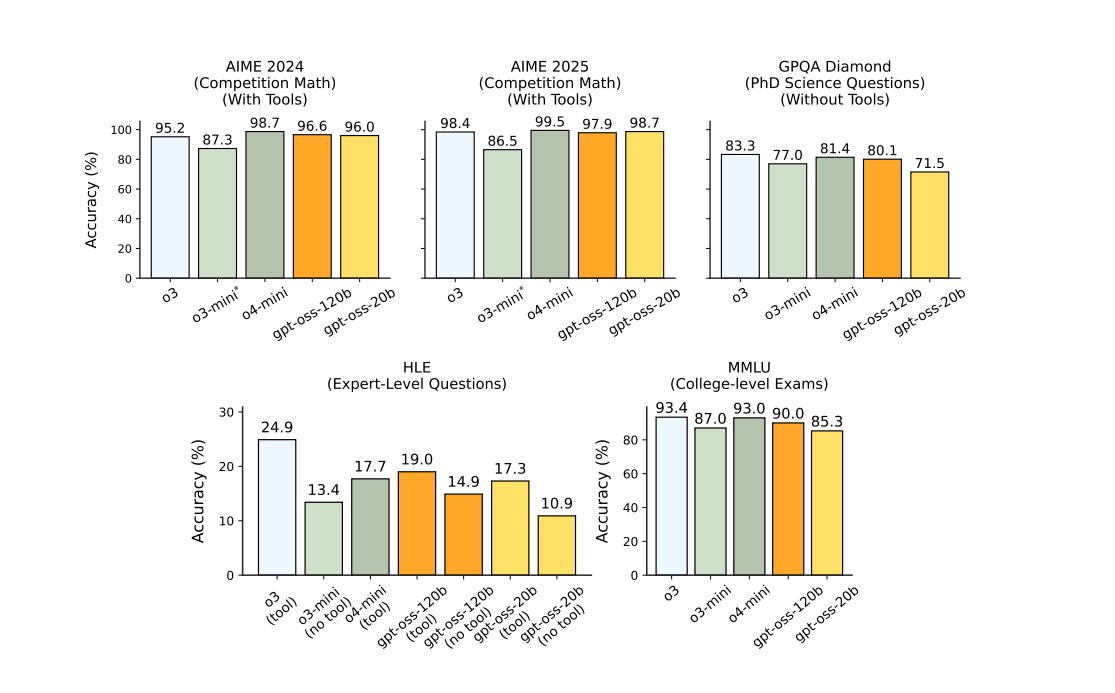
GPQA 화학, 생물학, 물리학 분야의 박사 수준 지식을 깊은 전문성이 필요한 객관식 문제로 테스트 | 80.1% Diamond 출처 |
IFEval 모델이 명시적 형식 지침을 정확히 따르고 적절한 출력을 생성하며 다양한 작업에서 일관된 지침 준수를 유지하는 능력 테스트 | - |
SimpleQA 간단한 질문의 정확성 평가 | 66.2% 출처 |
AIME 2024 | 69% 출처 |
AIME 2025 | 98.7% |
Aider Polyglot 다국어 프로그래밍 벤치마크. | - |
LiveCodeBench v5 실시간 프로그래밍 벤치마크 | 42.7% v5 출처 |
Global MMLU (Lite) 전 세계적으로 모델의 범용성을 평가하기 위한 간소화된 벤치마크 버전. | - |
MathVista 시각적 맥락에서 AI 모델의 수학적 추론 능력을 평가합니다 | - |
모바일 앱 | - |