
Веб-сайт Страница модели ИИ | |
Провайдер Организация, предоставляющая данную модель. | |
Чат Введите сообщение, чтобы начать общение | |
Дата выпуска Когда модель была впервые выпущена. | 10 месяцев назад Июл 09, 2025 |
Модальности Типы данных, которые может обрабатывать модель | текст изображения голос видео |
Поставщики API Провайдеры, предлагающие данную модель. (Этот список не является исчерпывающим.) | xAI |
Дата актуальности знаний Когда в последний раз обновлялись знания модели. | - |
Открытый исходный код Доступен ли исходный код модели для публичного использования. | Нет |
Стоимость ввода Стоимость обработки токенов в вашем запросе | $3.00 за миллион токенов |
Стоимость вывода Стоимость токенов, сгенерированных моделью | $15.00 за миллион токенов |
MMLU Massive Multitask Language Understanding – Тестирование знаний по 57 предметам, включая математику, историю, право и другие | - |
MMLU-Pro Улучшенный бенчмарк MMLU с более сложными вопросами, ориентированными на рассуждение, увеличенным числом вариантов ответов и сниженной чувствительностью к подсказкам | - |
MMMU Massive Multitask Multimodal Understanding – Тестирование понимания текста, изображений, аудио и видео | - |
HellaSwag Сложный бенчмарк для завершения предложений | - |
HumanEval Оценивает возможности генерации кода и решения задач | - |
MATH Тестирование математических навыков на разных уровнях сложности | - |
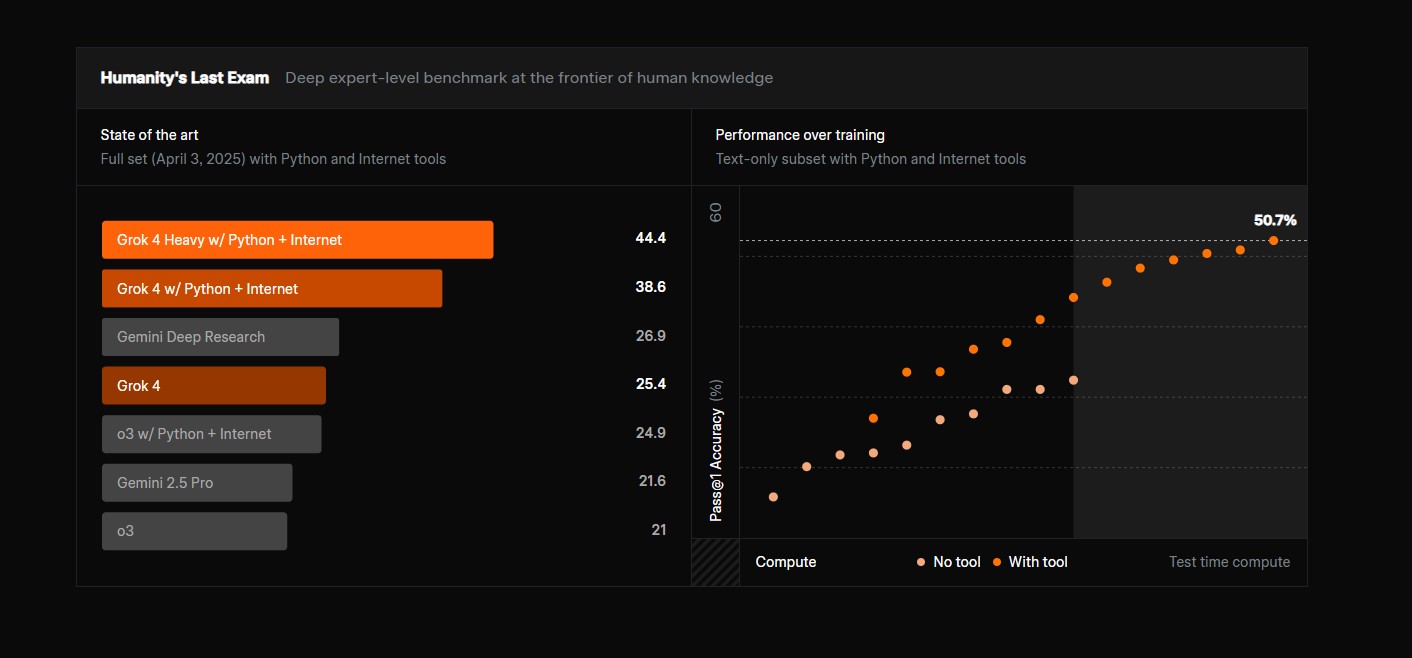
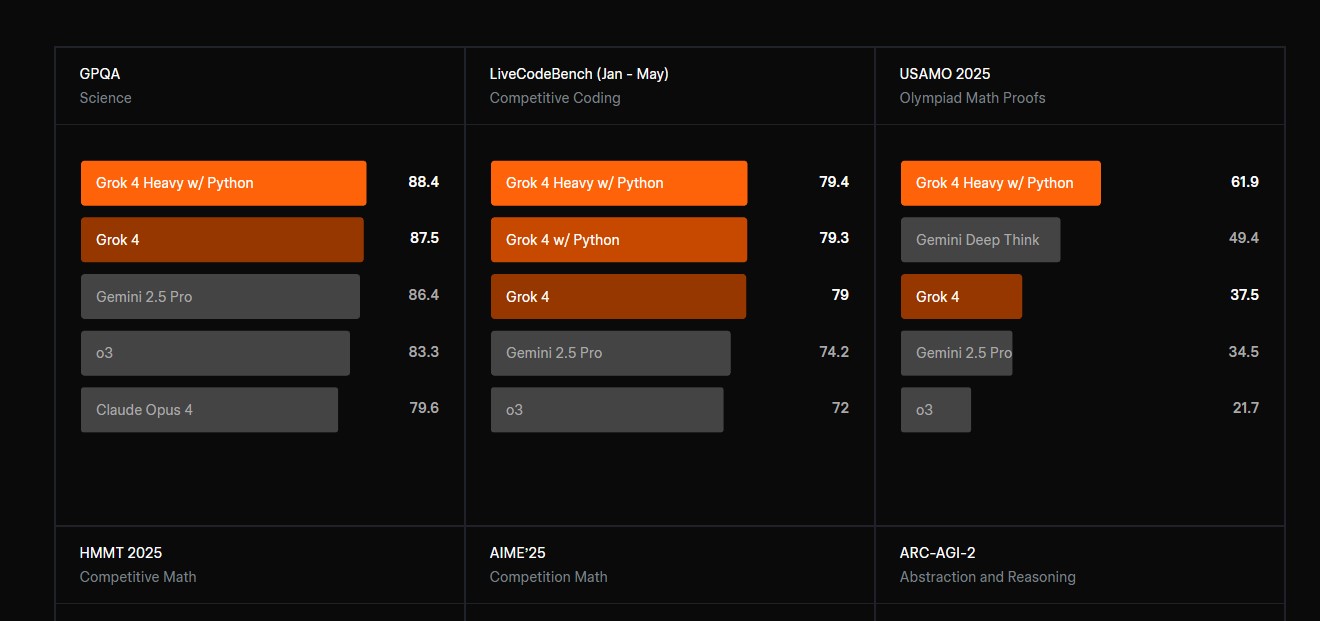
GPQA Тестирование знаний на уровне PhD в области химии, биологии и физики с помощью вопросов множественного выбора, требующих глубоких экспертных знаний | 87.5% Science Источник |
IFEval Оценивает способность модели точно следовать явным инструкциям по форматированию, генерировать соответствующие выходные данные и поддерживать последовательность инструкций в разных задачах | - |
SimpleQA Оценка точности простых вопросов | - |
AIME 2024 | - |
AIME 2025 | 91.7% Competition Math Источник |
Aider Polyglot Многоязычный программный бенчмарк. | - |
LiveCodeBench v5 Бенчмарк для программирования в реальном времени | 79% Competitive Coding Источник |
Global MMLU (Lite) Упрощенная версия бенчмарка для оценки универсальности моделей на глобальном уровне. | - |
MathVista Оценивает способности математического мышления моделей ИИ в визуальных контекстах | - |
Мобильное приложение | |
MathArena | |
| Средний балл | 89% |
| AIME 2025 Тест, основанный на задачах из конкурса по математике (American Invitational Mathematics Examination),предназначен для проверки математических навыков моделей. | 91% |
| HMMT February 2025 Тест, основанный на задачах из Harvard-MIT Mathematics Tournament, февраль 2025 года, предназначен для проверки математических навыков моделей. | 92% |
| BRUMO 2025 | 95% |
| SMT 2025 Тест, основанный на задачах из Stanford Math Tournament, 2025 года, предназначен для проверки математических навыков моделей. | 86% |
| CMIMC 2025 Тест, основанный на задачах из Canadian Mathematical Olympiad, 2025 года, предназначен для проверки математических навыков моделей. | 83% |
Compare AI. Test. Benchmarks. Чат-боты для мобильных приложений, Sketch
Copyright © 2026 All Right Reserved.