
वेबसाइट एआई मॉडल वेब पेज | |
प्रदाता इस मॉडल को प्रदान करने वाली इकाई। | |
चैट चैट शुरू करने के लिए एक संदेश दर्ज करें | |
रिलीज तिथि मॉडल पहली बार कब रिलीज हुआ था। | 10 महीने ago जुल 09, 2025 |
मोडलिटीज इस मॉडल द्वारा संसाधित किए जा सकने वाले डेटा के प्रकार | टेक्स्ट छवियां आवाज वीडियो |
एपीआई प्रदाता वे प्रदाता जो इस मॉडल को प्रदान करते हैं। (यह एक पूर्ण सूची नहीं है।) | xAI |
ज्ञान समाप्ति तिथि मॉडल का ज्ञान अंतिम बार कब अपडेट किया गया था। | - |
ओपन सोर्स क्या मॉडल का कोड सार्वजनिक उपयोग के लिए उपलब्ध है। | नहीं |
मूल्य निर्धारण इनपुट आपके प्रॉम्प्ट में टोकन प्रोसेसिंग की लागत | $3.00 प्रति मिलियन टोकन |
मूल्य निर्धारण आउटपुट मॉडल द्वारा उत्पन्न टोकन की लागत | $15.00 प्रति मिलियन टोकन |
एमएमएलयू मैसिव मल्टीटास्क भाषा समझ - गणित, इतिहास, कानून और अन्य सहित 57 विषयों में ज्ञान का परीक्षण | - |
एमएमएलयू-प्रो अधिक मजबूत एमएमएलयू बेंचमार्क जिसमें कठिन, तर्क-केंद्रित प्रश्न, बड़ा विकल्प सेट, और कम प्रॉम्प्ट संवेदनशीलता शामिल है | - |
एमएमएमयू मैसिव मल्टीटास्क मल्टीमॉडल समझ - टेक्स्ट, छवियों, ऑडियो और वीडियो में समझ का परीक्षण | - |
हेलास्वैग एक चुनौतीपूर्ण वाक्य पूर्णता बेंचमार्क | - |
ह्यूमनएवैल कोड जनरेशन और समस्या-समाधान क्षमताओं का मूल्यांकन करता है | - |
मैथ विभिन्न कठिनाई स्तरों पर गणितीय समस्या-समाधान क्षमताओं का परीक्षण | - |
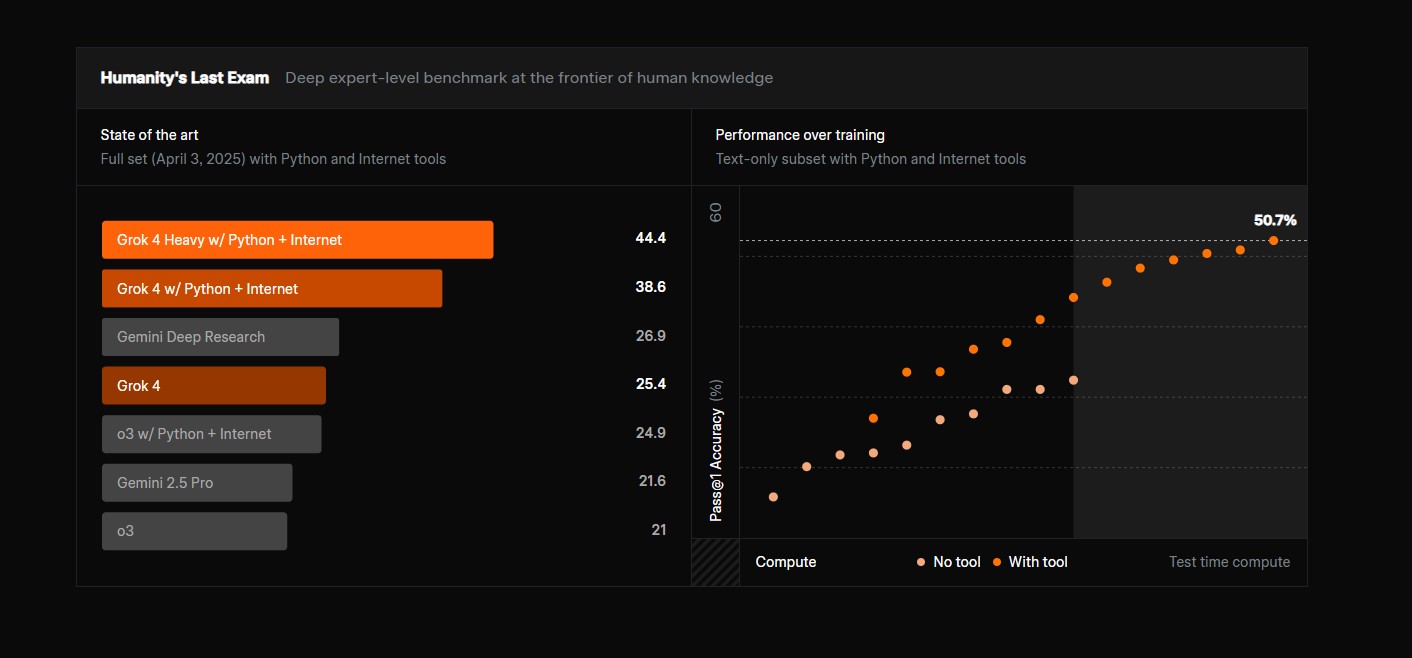
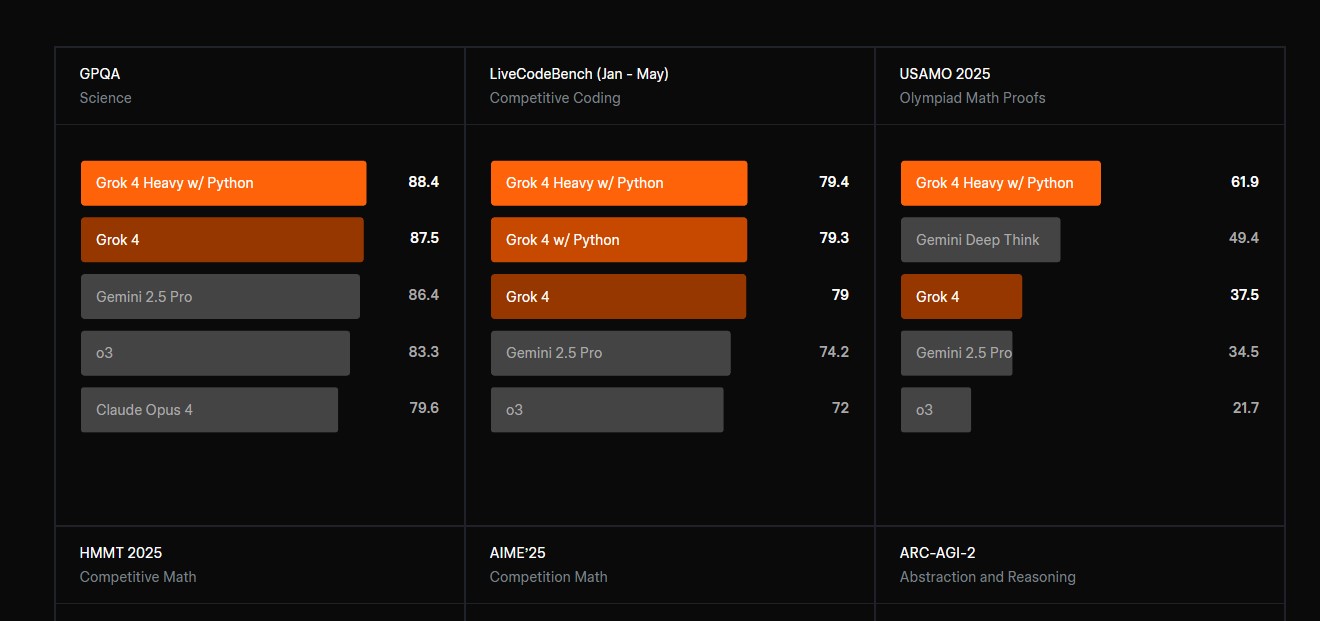
जीपीक्यूए रसायन विज्ञान, जीव विज्ञान और भौतिकी में पीएचडी-स्तर के ज्ञान का बहुविकल्पीय प्रश्नों के माध्यम से परीक्षण जो गहरे डोमेन विशेषज्ञता की आवश्यकता रखते हैं | 87.5% Science स्रोत |
आईएफइवैल मॉडल की स्पष्ट स्वरूपण निर्देशों का सटीक पालन करने, उपयुक्त आउटपुट उत्पन्न करने, और विभिन्न कार्यों में लगातार निर्देश अनुपालन बनाए रखने की क्षमता का परीक्षण | - |
SimpleQA साधारण प्रश्नों की सटीकता का आकलन | - |
AIME 2024 | - |
AIME 2025 | 91.7% Competition Math स्रोत |
Aider Polyglot बहुभाषी प्रोग्रामिंग बेंचमार्क। | - |
LiveCodeBench v5 रीयल-टाइम प्रोग्रामिंग के लिए बेंचमार्क | 79% Competitive Coding स्रोत |
वैश्विक MMLU (लाइट) वैश्विक स्तर पर मॉडलों की सार्वभौमिकता का आकलन करने के लिए बेंचमार्क का सरलीकृत संस्करण। | - |
MathVista दृश्य संदर्भों में AI मॉडलों की गणितीय तर्क क्षमताओं का मूल्यांकन | - |
मोबाइल एप्लिकेशन | |
MathArena | |
| औसत स्कोर | 89% |
| AIME 2025 अमेरिकन इनविटेशनल मैथमेटिक्स एग्जामिनेशन (American Invitational Mathematics Examination) के प्रश्नों पर आधारित परीक्षण, मॉडल की गणितीय क्षमताओं को परखने के लिए बनाया गया है। | 91% |
| HMMT February 2025 फरवरी 2025 हार्वर्ड-MIT गणित टूर्नामेंट के प्रश्नों पर आधारित परीक्षण, मॉडल की गणितीय क्षमताओं को परखने के लिए बनाया गया है। | 92% |
| BRUMO 2025 | 95% |
| SMT 2025 2025 स्टैनफोर्ड गणित टूर्नामेंट के प्रश्नों पर आधारित परीक्षण, मॉडल की गणितीय क्षमताओं को परखने के लिए बनाया गया है। | 86% |
| CMIMC 2025 2025 कैनेडियन मैथमैटिकल ओलंपियाड के प्रश्नों पर आधारित परीक्षण, मॉडल की गणितीय क्षमताओं को परखने के लिए बनाया गया है। | 83% |
Compare AI. Test. Benchmarks. मोबाइल ऐप्स चैटबॉट्स, Sketch
Copyright © 2026 All Right Reserved.