

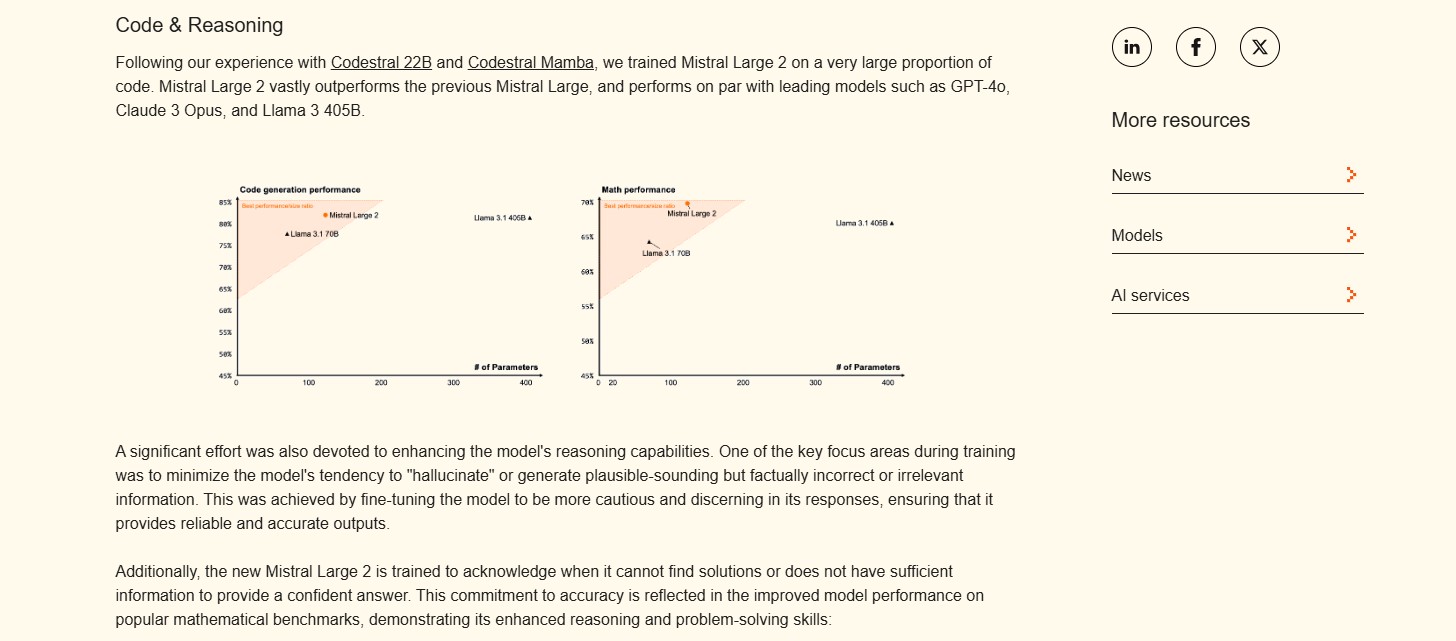
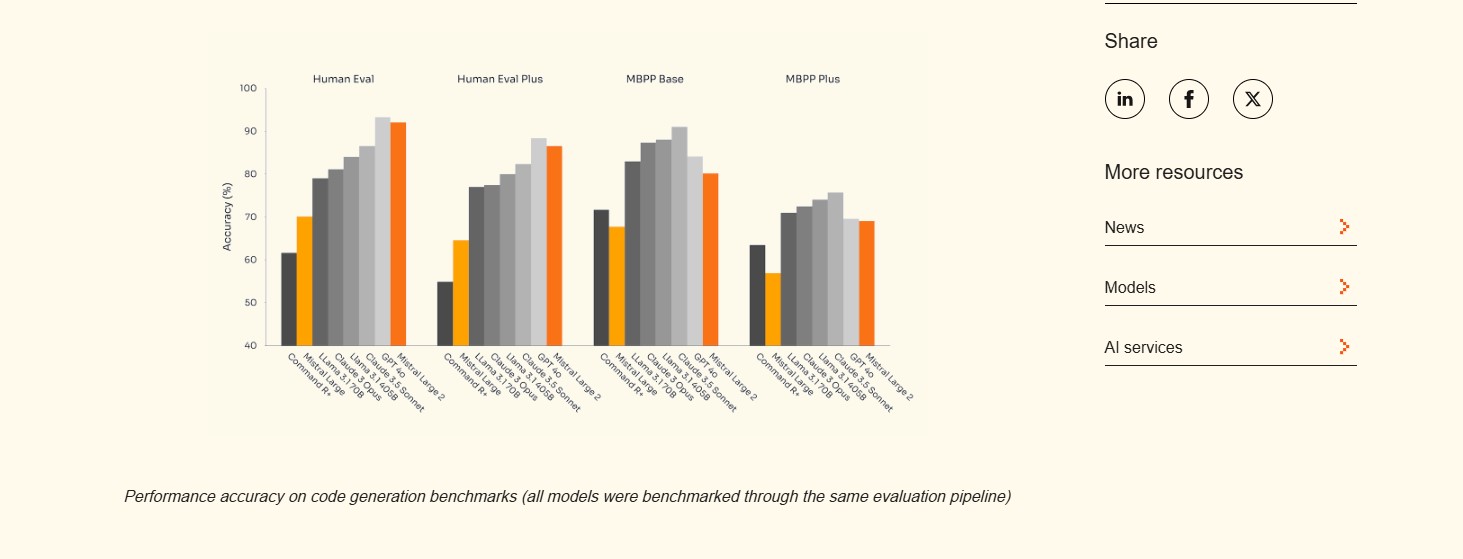

Mistral Large 2, opracowany przez Mistral, oferuje okno kontekstowe o rozmiarze 128 000 tokenów i jest wyceniony na 3,00 USD za milion tokenów wejściowych oraz 9,00 USD za milion tokenów wyjściowych. Wydany 24 lipca 2024 roku model uzyskał wynik 84,0 w benchmarku MMLU w ocenie 5-shot, wykazując silne osiągi w różnych zadaniach.
Strona internetowa Strona internetowa modelu AI | |
Dostawca Podmiot dostarczający ten model. | |
Czat Wpisz wiadomość, aby rozpocząć czat | - |
Data wydania Kiedy model został po raz pierwszy wydany. | 1 rok ago Cze 24, 2024 |
Modalności Rodzaje danych, które ten model może przetwarzać | tekst |
Dostawcy API Dostawcy oferujący ten model. (To nie jest wyczerpująca lista.) | Azure AI, AWS Bedrock, Google AI Studio, Vertex AI, Snowflake Cortex |
Data ostatniej aktualizacji wiedzy Kiedy wiedza modelu była ostatnio aktualizowana. | Nieznane |
Open Source Czy kod modelu jest dostępny do publicznego użytku. | Tak |
Cena za wejście Koszt przetwarzania tokenów w Twoich promptach | $3.00 za milion tokenów |
Cena za wyjście Koszt za tokeny wygenerowane przez model | $9.00 za milion tokenów |
MMLU Massive Multitask Language Understanding - Testuje wiedzę z 57 dziedzin, w tym matematyki, historii, prawa i innych | 84% 5-shot Źródło |
MMLU-Pro Bardziej zaawansowane benchmarki MMLU z trudniejszymi pytaniami skupionymi na rozumowaniu, większym zestawem wyborów i zmniejszoną wrażliwością na prompty | 50.69% Źródło |
MMMU Massive Multitask Multimodal Understanding - Testuje rozumienie tekstu, obrazów, dźwięku i wideo | Niedostępne |
HellaSwag Wymagające benchmarki uzupełniania zdań | Niedostępne |
HumanEval Ocenia możliwości generowania kodu i rozwiązywania problemów | Niedostępne |
MATH Testuje umiejętności rozwiązywania problemów matematycznych na różnych poziomach trudności | 1.13% Źródło |
GPQA Testuje wiedzę na poziomie doktorskim z chemii, biologii i fizyki poprzez pytania wielokrotnego wyboru wymagające głębokiej wiedzy specjalistycznej | 24.94% |
IFEval Testuje zdolność modelu do dokładnego przestrzegania wyraźnych instrukcji formatowania, generowania odpowiednich wyników i utrzymania spójnego przestrzegania instrukcji w różnych zadaniach | 84.01% |
SimpleQA Ocena dokładności prostych pytań | - |
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot Wielojęzyczny benchmark programistyczny. | - |
LiveCodeBench v5 Benchmark programowania w czasie rzeczywistym | - |
Global MMLU (Lite) Uproszczona wersja benchmarku do oceny uniwersalności modeli na poziomie globalnym. | - |
MathVista Ocenia zdolności rozumowania matematycznego modeli AI w kontekstach wizualnych | - |
Aplikacja mobilna | - |
Compare AI. Test. Benchmarks. Chatboty mobilne, Sketch
Copyright © 2026 All Right Reserved.