


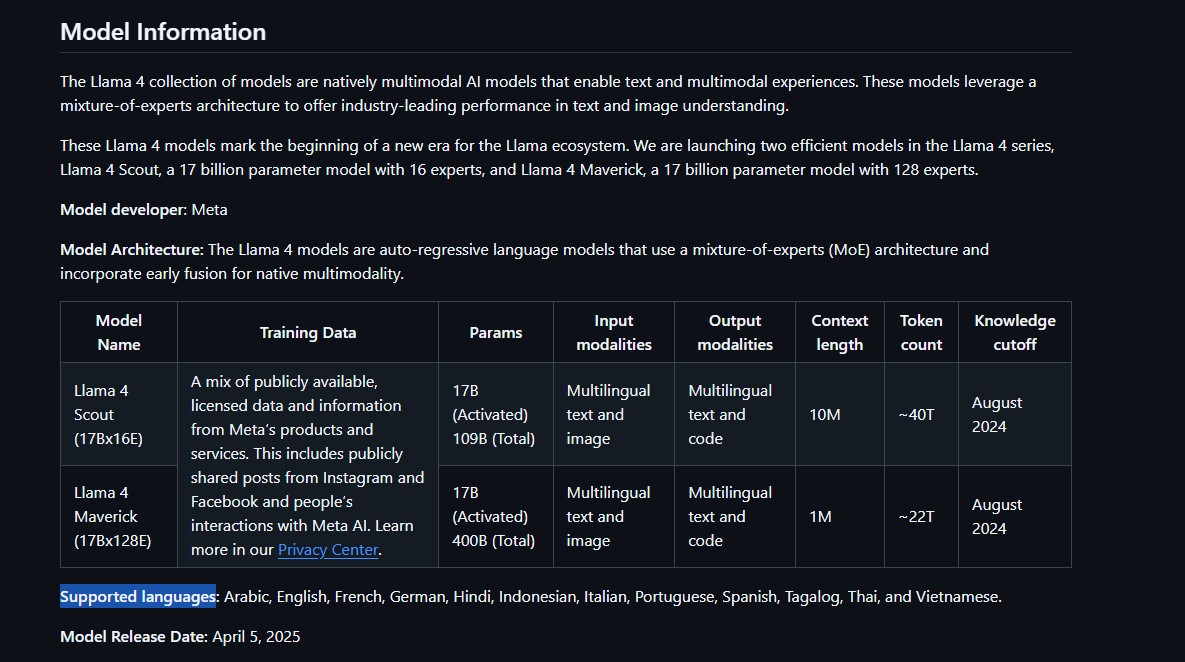
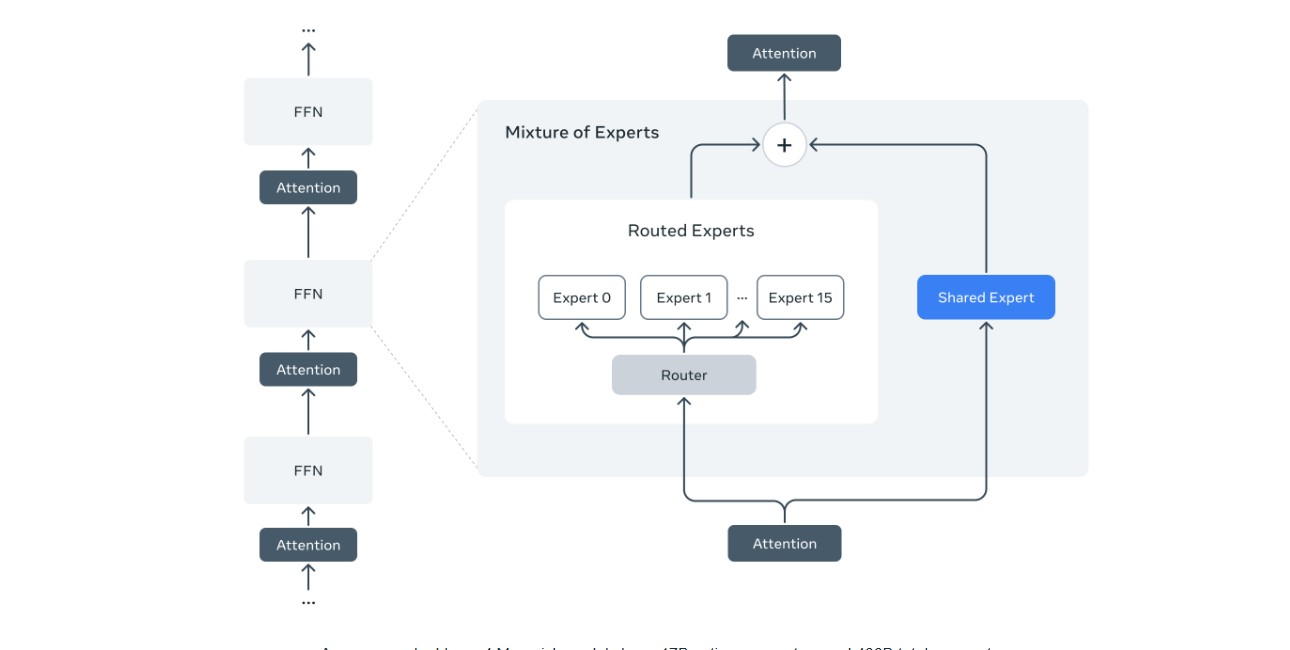
LLaMA 4 Maverick은 128명의 전문가로 구성된 혼합 전문가 아키텍처에서 170억 개의 활성 파라미터를 사용하는 첨단 멀티모달 모델로, 총 4,000억 개의 파라미터를 갖고 있습니다. GPT-4o 및 Gemini 2.0 Flash 등 주요 경쟁 모델보다 다양한 벤치마크에서 뛰어난 성능을 보이며, DeepSeek V3와 유사한 추론 및 코딩 능력을 절반 이하의 활성 파라미터로 구현합니다. 효율성과 확장성을 위해 설계된 Maverick은 최고 수준의 성능 대비 비용 효율성을 자랑하며, 실험용 챗봇 버전은 LMArena에서 ELO 점수 1417을 기록했습니다. 이처럼 대규모 모델임에도 불구하고 단일 NVIDIA H100 호스트에서 실행이 가능하여 배포가 간편합니다.
웹사이트 AI 모델 웹페이지 | |
제공자 이 모델을 제공하는 주체. | |
채팅 채팅을 시작하려면 메시지를 입력하세요 | - |
출시일 모델이 처음 출시된 날짜. | 1 년 ago 4월 05, 2025 |
모달리티 이 모델이 처리할 수 있는 데이터 유형 | 텍스트 이미지 비디오 |
API 제공자 이 모델을 제공하는 업체들. (전체 목록이 아님) | Meta AI, Hugging Face, Fireworks, Together, DeepInfra |
지식 업데이트 종료일 모델의 지식이 마지막으로 업데이트된 날짜. | 2024-08 |
오픈 소스 모델 코드가 공개적으로 사용 가능한지 여부. | 예 (출처) |
입력 가격 프롬프트 토큰 처리 비용 | 정보 없음 |
출력 가격 모델이 생성한 토큰 비용 | 정보 없음 |
MMLU Massive Multitask Language Understanding - 수학, 역사, 법학 등 57개 과목에 걸친 지식 테스트 | 정보 없음 |
MMLU-Pro 더 어렵고 추론 중심의 질문, 더 큰 선택지, 프롬프트 민감도 감소로 강화된 MMLU 벤치마크 | 80.5% 출처 |
MMMU Massive Multitask Multimodal Understanding - 텍스트, 이미지, 오디오, 비디오에 걸친 이해력 테스트 | 73.4% 출처 |
HellaSwag 도전적인 문장 완성 벤치마크 | 정보 없음 |
HumanEval 코드 생성 및 문제 해결 능력 평가 | 정보 없음 |
MATH 다양한 난이도의 수학 문제 해결 능력 테스트 | 정보 없음 |
GPQA 화학, 생물학, 물리학 분야의 박사 수준 지식을 깊은 전문성이 필요한 객관식 문제로 테스트 | 69.8% Diamond 출처 |
IFEval 모델이 명시적 형식 지침을 정확히 따르고 적절한 출력을 생성하며 다양한 작업에서 일관된 지침 준수를 유지하는 능력 테스트 | 정보 없음 |
SimpleQA 간단한 질문의 정확성 평가 | - |
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot 다국어 프로그래밍 벤치마크. | - |
LiveCodeBench v5 실시간 프로그래밍 벤치마크 | - |
Global MMLU (Lite) 전 세계적으로 모델의 범용성을 평가하기 위한 간소화된 벤치마크 버전. | - |
MathVista 시각적 맥락에서 AI 모델의 수학적 추론 능력을 평가합니다 | - |
모바일 앱 | - |
VideoGameBench | |
| 총점 | 0% |
| Doom II | 0% |
| Dream DX | 0% |
| Awakening DX | 0% |
| Civilization I | 0% |
| Pokemon Crystal | 0% |
| The Need for Speed | 0% |
| The Incredible Machine | 0% |
| Secret Game 1 | %0 |
| Secret Game 2 | 0% |
| Secret Game 3 | 0% |