
ウェブサイト AIモデルのウェブページ | |
プロバイダー このモデルを提供するエンティティ。 | |
チャット メッセージを入力してチャットを開始 | |
リリース日 モデルが最初にリリースされた日時。 | 1 年 ago 4月 14, 2025 |
モダリティ このモデルが処理できるデータの種類 | テキスト 画像 |
APIプロバイダー このモデルを提供するプロバイダー。(これは完全なリストではありません。) | OpenAI API |
知識のカットオフ日 モデルの知識が最後に更新された日時。 | - |
オープンソース モデルのコードが公開されているかどうか。 | いいえ |
入力料金 プロンプト内のトークン処理のコスト | $0.10 100万トークンあたり |
出力料金 モデルによって生成されたトークンのコスト | $0.40 100万トークンあたり |
MMLU Massive Multitask Language Understanding - 数学、歴史、法律など57の科目にわたる知識をテスト | 80.1% ソース |
MMLU-Pro より堅牢なMMLUベンチマークで、難易度の高い推論中心の質問、より大きな選択肢セット、プロンプト感度の低減を特徴とする | - |
MMMU Massive Multitask Multimodal Understanding - テキスト、画像、音声、動画にわたる理解をテスト | 55.4% ソース |
HellaSwag 挑戦的な文完成ベンチマーク | - |
HumanEval コード生成と問題解決能力を評価 | - |
MATH さまざまな難易度レベルでの数学的問題解決能力をテスト | - |
GPQA 化学、生物学、物理学における博士レベルの知識を、深い専門知識を必要とする多肢選択問題でテスト | 50.3% Diamond ソース |
IFEval モデルが明示的なフォーマット指示に正確に従い、適切な出力を生成し、異なるタスク間で一貫した指示遵守を維持する能力をテスト | 74.5% ソース |
SimpleQA シンプルな質問の精度評価 | - |
AIME 2024 | 29.4% ソース |
AIME 2025 | - |
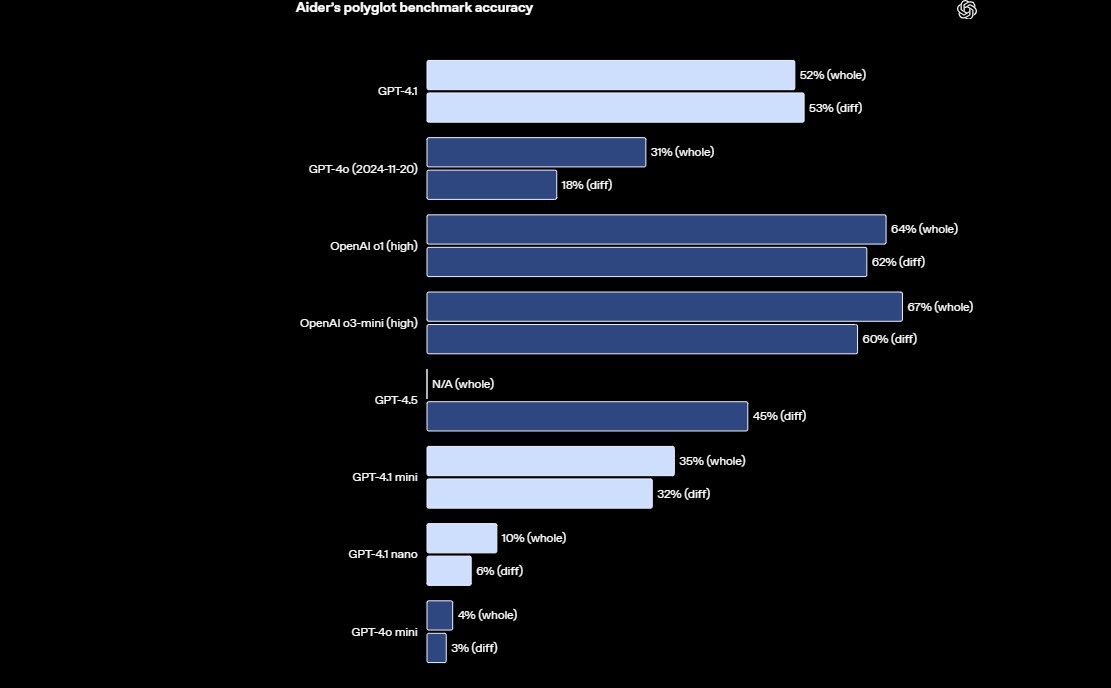
Aider Polyglot 多言語プログラミングベンチマーク | - |
LiveCodeBench v5 リアルタイムプログラミングのベンチマーク | - |
Global MMLU (Lite) モデルの汎用性をグローバルレベルで評価するための簡易版ベンチマーク。 | 66.9% ソース |
MathVista 視覚的な文脈におけるAIモデルの数学的推論能力を評価します | 56.2% Image Reasoning ソース |
モバイルアプリケーション |
Compare AI. Test. Benchmarks. モバイルアプリチャットボット, Sketch
Copyright © 2026 All Right Reserved.