
Найновіша модель GPT-4.5 від OpenAI, випущена 27 лютого 2025 року, є революційним штучним інтелектом із 12,8 трильйонами параметрів і контекстним вікном у 128 000 токенів. Вона має розширені загальні знання, покращений емоційний інтелект, обробку мультимодальних вхідних даних (текст і зображення),складний виклик функцій і потокові відповіді в реальному часі. Спочатку розгорнута для користувачів ChatGPT Pro, а пізніше доступна для передплатників Plus і Team, вона надає відповіді зі швидкістю приблизно 37 токенів на секунду, що робить її відмінним вибором для завдань, які вимагають високого рівня міркувань і емоційної глибини.
Веб-сайт Веб-сторінка моделі ШІ | |
Постачальник Організація, яка надає цю модель. | |
Чат Введіть повідомлення, щоб почати спілкування | - |
Дата випуску Дата першого випуску моделі. | 1 рік ago Лют 27, 2025 |
Модальності Типи даних, які може обробляти ця модель | текст зображення |
Постачальники API Постачальники, які пропонують цю модель. (Це не вичерпний список.) | OpenAI, Azure OpenAI Service |
Дата оновлення знань Дата останнього оновлення знань моделі. | 2023-10 |
Відкритий код Чи доступний код моделі для публічного використання. | Ні |
Вартість введення Вартість обробки токенів у ваших запитах | $75.00 за мільйон токенів |
Вартість виведення Вартість токенів, згенерованих моделлю | $150.00 за мільйон токенів |
MMLU Massive Multitask Language Understanding - Тестує знання з 57 предметів, включаючи математику, історію, право та інше | Недоступно |
MMLU-Pro Більш надійний тест MMLU із складнішими питаннями, орієнтованими на міркування, більшим набором варіантів і зменшеною чутливістю до запитів | Недоступно |
MMMU Massive Multitask Multimodal Understanding - Тестує розуміння тексту, зображень, аудіо та відео | 74.4% Джерело |
HellaSwag Складний тест на завершення речень | Недоступно |
HumanEval Оцінює можливості генерації коду та вирішення задач | Недоступно |
MATH Тестує математичні навички вирішення задач різного рівня складності | Недоступно |
GPQA Тестує знання на рівні PhD з хімії, біології та фізики через багатозначні питання, що вимагають глибоких знань у галузі | 71.4% science Джерело |
IFEval Тестує здатність моделі точно дотримуватися явних інструкцій щодо форматування, генерувати відповідні результати та підтримувати послідовне дотримання інструкцій у різних завданнях | Недоступно |
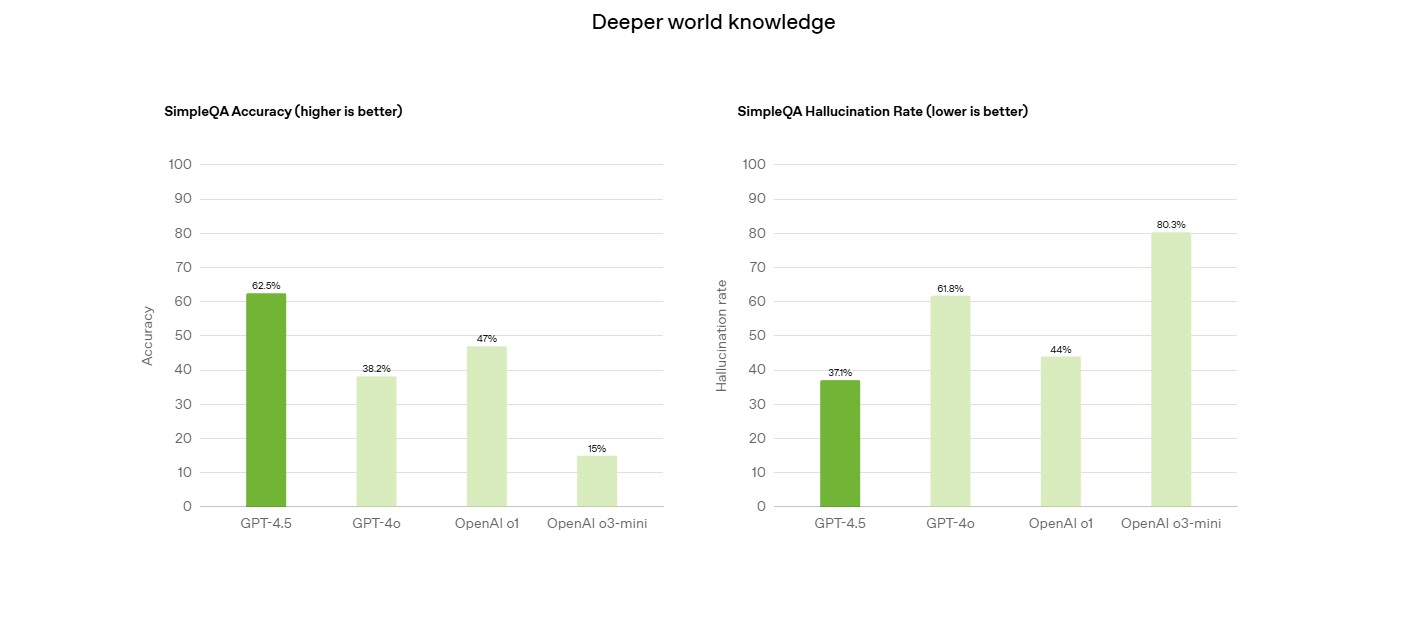
SimpleQA Оцінка точності простих запитань | - |
AIME 2024 | - |
AIME 2025 | - |
Aider Polyglot Багатомовний програмний бенчмарк. | - |
LiveCodeBench v5 Бенчмарк для програмування в реальному часі | - |
Global MMLU (Lite) Спрощена версія бенчмарку для оцінки універсальності моделей на глобальному рівні. | - |
MathVista Оцінює математичні здібності ШІ моделей у візуальних контекстах | - |
Мобільний додаток |
Compare AI. Test. Benchmarks. Чат-боти для мобільних застосунків, Sketch
Copyright © 2026 All Right Reserved.